How is a professional search carried out? Survey of programs for the search for documents and data. We punch login on social networks
Introduction
Currently, the Internet unites hundreds of millions of servers that host billions of different sites and individual files containing various kinds of information. It's a giant repository of information. There are various methods of searching for information on the Internet.
Search by known address. The required addresses are taken from directories. Knowing the address, it is enough to enter it into the address bar of the Browser.
Example 1. www.gov.ru - the server of the state authorities of Russia.
Address construction by the user. Knowing the Internet address generation system, you can construct addresses when searching for Web sites.
It is necessary to add a thematic or geographical domain to a keyword (the name of a company, enterprise, organization or a simple English noun), and intuition must be connected.
Example 2 Commercial Web Page Addresses:
www.samsung.com (company SAMSUNG),
www.mtv.com (MTV music news).
Example 3. Addresses of educational institutions:
www.ntu.edu (US National University).
Internet search engines
To search for information on the Internet, special information retrieval systems have been developed. Search engines have a regular address and are displayed as a Web page containing special tools for organizing search (search string, subject catalog, links). To call a search engine, just enter its address in the address bar of the Browser.
According to the LiveInternet.ru statistics service, the distribution search engines in Russia, something like this:
2) Google - 35.0%
3) Mail.ru search - 8.3%
4) Rambler - 0.9%
According to the method of organizing information, information retrieval systems are divided into two types: classification (rubricators) and dictionary.
Rubricators (classifiers)- search engines that use a hierarchical (tree-like) organization of information. When searching for information, the user looks through thematic headings, gradually narrowing the search field (for example, if you need to find the meaning of a word, then first you need to find a dictionary in the classifier, and then find the right word in it).
Dictionary search engines are powerful automatic software and hardware systems. With their help, information on the Internet is viewed (scanned). Data on the location of this or that information is entered into special reference books-indexes. In response to the request, a search is performed in accordance with the query string. As a result, the user is offered those addresses (URLs) where the searched word or group of words was found at the time of scanning. By selecting any of the proposed links, you can go to the found document. Most modern search engines are mixed.
The most famous and popular search engines:
There are systems that specialize in searching for information resources in various areas.
https://my.mail.ru
https://ru-ru.facebook.com
https://twitter.com
https://www.tumblr.com
https://www.instagram.com etc.
Subject search engines:
Software search:
Catalogs (thematic collections of links with annotations):
http://www.atrus.ru
Query Execution Rules
In each search engine, in the Help section, you can get information on how to search, how to compose a query string. Below is information about a typical, "average" query language.
Simple Request
Enter one word that defines the search topic. For example, in the Rambler.ru search engine, it is enough to enter: automation.
Documents are found that contain the words specified in the request. All forms of Russian words are recognized, as a rule, the case of letters is ignored.
You can use the character "*" or "?" in the query. Sign "?" in the keyword, one character is replaced, which can be replaced by any letter, and the character "*" is a sequence of characters.
For example, a query automaton* will find documents that include the words automatic, automatic, and so on.
Complex request
Often there is a need to combine keywords to get more specific information. In this case, additional linking words, functions, operators, symbols, combinations of operators separated by brackets are used.
For example, the query music & (beatles beatles) means that the user is looking for documents containing the words music and beatles or music and beatles.
List of search servers and directories
| The address | Description | |
| www.excite.com | Search engine with node reviews and guides | |
| www.alta-vista.com | Search server, advanced search capabilities available | |
| www.hotbot.com | search server | |
| www.ifoseek.com | Search Server (easy to use) | |
| www.ipl.org | Internet Publik library, a public library operating as part of the World Village project | |
| www.wisewire.com | WiseWire - organization of search using artificial intelligence | |
| www.webcrawler.com | WebCrawler - search server, easy to use | |
| www.yahoo.com | Web catalog and interface for accessing full-text search on the AltaVista server | |
| www.aport.ru | Aport - Russian language search server | |
| www.yandex.ru | Yandex - Russian-language search server | |
| www.rambler.ru | Rambler - Russian-language search server | |
| Internet Help Resources | ||
| www.yellow.com | Internet Yellow Pages | |
| monk.newmail.ru | Search engines of various profiles | |
| www.top200.ru | Top 200 Websites | |
| www.allru.net | ||
| www.ru | Catalog of Russian Internet resources | |
| www.allru.net/z09.htm | Educational Resources | |
| www.students.ru | Russian student server | |
| www.cdo.ru/index_new.asp | Distance Learning Center | |
| www.open.ac.uk | Open University UK | |
| www.ntu.edu | US National University | |
| www.translate.ru | Electronic text translator | |
| www.pomorsu.ru/guide.library.html | List of links to net libraries | |
| www.elibrary.ru | Scientific electronic library | |
| www.citforum.ru | E-library | |
| www.infamed.com/psy | Psychological tests | |
| www.pokoleniye.ru | Internet Education Federation website | |
| www.metod.narod.ru | Educational Resources | |
| www.spb.osi.ru/ic/distant | Distance learning on the Internet | |
| www.examen.ru | Exams and tests | |
| www.kbsu.ru/~book/ | Computer science textbook | |
| Mega.km.ru | Encyclopedias and dictionaries | |
Professional search for information on the Internet
Searching for information is one of the most common and at the same time the most difficult tasks that any user has to face on the Web. However, if for an ordinary member of the network community, knowledge of effective information retrieval methods is a desirable, but far from obligatory quality, then for information professionals, the ability to quickly navigate the Internet resources and find the required sources is one of the basic qualification skills.
The reason for the difficulties that arise in information retrieval on the Internet is determined by two main factors. First, the number of sources on the Web is extremely large. At the end of 2001, the most rough estimates indicated an approximate figure of 7.5 billion documents located on servers around the world. Secondly, the amount of information on the Web is not only colossal in volume, but also extremely dynamic. In the half minute that you spent reading the first lines of this section, about a hundred new or changed documents appeared in the virtual universe, dozens were moved to new addresses, and units ceased to exist forever. The Internet never "sleeps", just as our planet never "sleeps", along which a wave of human business activity rolls continuously in exact accordance with the change of time zones.
Unlike a stable and controlled collection of documents in a library, on the Web we are dealing with a gigantic and constantly changing information array, the search for data in which is a very, very complex process. The situation is often very reminiscent of the well-known task of finding a needle in a haystack, and sometimes information of great value remains unclaimed solely because of the difficulty of finding it.
Most of the users of global computer networks. Both amateurs and professionals often use the same tools. However, the results of the searches and the time spent on them differ to a very large extent.
The purpose of this section is to get acquainted in detail with the tools and methods of information retrieval and develop sustainable skills for professional search on the Web of all types of data: from texts in any format to video and animation.
What is it
DuckDuckGo is a fairly well-known open source search engine. The servers are located in the USA. In addition to its own robot, the search engine uses the results of other sources: Yahoo, Bing, Wikipedia.
The better
DuckDuckGo positions itself as the ultimate privacy and privacy search. The system does not collect any data about the user, does not store logs (no search history), use cookies maximally limited.
DuckDuckGo does not collect or share personal information from users. This is our privacy policy.
Gabriel Weinberg, founder of DuckDuckGo
Why do you need this
All major search engines try to personalize search results based on data about the person in front of the monitor. This phenomenon is called "filter bubble": the user sees only those results that are consistent with his preferences or that the system considers as such.
Forms an objective picture that does not depend on your past behavior on the Web, and eliminates thematic google ads and "Yandex", based on your requests. With the help of DuckDuckGo, it is easy to search for information in foreign languages, while Google and Yandex prefer Russian-language sites by default, even if the query is entered in another language.

What is it
not Evil is a system that searches the anonymous Tor network. To use it, you need to go to this network, for example, by launching a specialized .
not Evil is not the only search engine of its kind. There is LOOK (default search in the Tor browser, accessible from the regular Internet) or TORCH (one of the oldest search engines on the Tor network) and others. We settled on not Evil because of the unmistakable allusion to Google (just look at the start page).
The better
He is looking for where Google, Yandex and other search engines are denied access in principle.
Why do you need this
There are many resources on the Tor network that cannot be found on the law-abiding Internet. And their number will grow as the control of the authorities over the contents of the Web tightens. Tor is a kind of network within the Web with its social networks, torrent trackers, media, marketplaces, blogs, libraries, and so on.
3. YaCy

What is it
YaCy is a decentralized search engine that works on the principle of P2P networks. Each computer on which the main software module is installed scans the Internet on its own, that is, it is an analogue of a search robot. The results obtained are collected in a common database, which is used by all YaCy participants.
The better
It is difficult to say here whether this is better or worse, since YaCy is a completely different approach to organizing search. The lack of a single server and owner company makes the results completely independent of anyone's preferences. The autonomy of each node excludes censorship. YaCy is capable of searching the deep web and non-indexed public networks.
Why do you need this
If you are a supporter of open source software and a free Internet that is not influenced by government agencies and large corporations, then YaCy is your choice. It can also be used to organize searches within a corporate or other autonomous network. And although YaCy is not very useful in everyday life, it is a worthy alternative to Google in terms of the search process.
4. Pipl

What is it
Pipl is a system designed to search for information about a specific person.
The better
The authors of Pipl claim that their specialized algorithms search more efficiently than "regular" search engines. In particular, social media profiles, comments, lists of members and various databases where information about people is published, such as databases of court decisions, are prioritized. Pipl's leadership in this area is confirmed by Lifehacker.com, TechCrunch and other publications.
Why do you need this
If you need to find information about a person living in the US, then Pipl will be much more efficient than Google. Databases of Russian courts, apparently, are inaccessible to the search engine. Therefore, he does not cope so well with the citizens of Russia.

What is it
FindSounds is another specialized search engine. Searches open sources for various sounds: house, nature, cars, people, and so on. The service does not support requests in Russian, but there is an impressive list of Russian-language tags that you can search for.
The better
In the issuance of only sounds and nothing more. In the settings you can set the desired format and sound quality. All found sounds are available for download. There is a pattern search.
Why do you need this
If you need to quickly find the sound of a musket shot, the blow of a sucking woodpecker, or the cry of Homer Simpson, then this service is for you. And we chose this only from the available Russian-language queries. In English, the spectrum is even wider.
Seriously, a specialized service implies a specialized audience. But will it come in handy for you too?

What is it
Wolfram|Alpha is a computational search engine. Instead of links to articles containing keywords, it gives a ready-made answer to the user's request. For example, if you enter “compare the population of New York and San Francisco” in English into the search form, then Wolfram|Alpha will immediately display tables and graphs with a comparison.
The better
This service is better than others for finding facts and calculating data. Wolfram|Alpha collects and organizes knowledge available on the Web from various fields, including science, culture and entertainment. If this database contains a ready answer to a search query, the system shows it, if not, it calculates and displays the result. In this case, the user sees only and nothing more.
Why do you need this
If you are, for example, a student, analyst, journalist, or researcher, you can use Wolfram|Alpha to find and calculate data related to your activities. The service does not understand all requests, but is constantly evolving and becoming smarter.

What is it
Metasearch engine Dogpile displays a combined list of results from Google, Yahoo and other popular search engines.
The better
First, Dogpile displays fewer ads. Secondly, the service uses a special algorithm to find and display the best results from different search engines. According to the developers of Dogpile, their system generates the most complete issue on the entire Internet.
Why do you need this
If you can't find information on Google or another standard search engine, look it up in several search engines at once using Dogpile.

What is it
BoardReader is a text search system for forums, Q&A services and other communities.
The better
The service allows you to narrow the search field to social sites. Thanks to special filters, you can quickly find posts and comments that match your criteria: language, publication date, and site name.
Why do you need this
BoardReader can be useful for PR specialists and other media professionals who are interested in the opinion of the mass media on certain issues.
Finally
The life of alternative search engines is often fleeting. Lifehacker asked the former CEO of the Ukrainian branch of Yandex Sergey Petrenko about the long-term prospects for such projects.

Sergey Petrenko
Former CEO"Yandex.Ukraine".
As for the fate of alternative search engines, it is simple: to be very niche projects with a small audience, therefore, without clear commercial prospects, or, conversely, with the complete clarity of their absence.
If you look at the examples in the article, you can see that such search engines either specialize in a narrow but in-demand niche, which, perhaps only so far, has not grown enough to be noticeable on the radars of Google or Yandex, or are testing an original hypothesis in ranking, which is not yet applicable in conventional search.
For example, if a Tor search suddenly turns out to be in demand, that is, at least a percentage of the Google audience will need the results from there, then, of course, ordinary search engines will begin to solve the problem of how to find them and show them to the user. If the behavior of the audience shows that a significant proportion of users in a significant number of queries seem to be more relevant results, data without taking into account factors that depend on the user, then Yandex or Google will begin to give such results.
"To be better" in the context of this article does not mean "to be better at everything". Yes, in many aspects our heroes are far from Yandex (even far from Bing). But each of these services gives the user something that the giants of the search industry cannot offer. Surely you also know similar projects. Share with us - let's discuss.
Checking a nickname for dozens of services at a time, counting reposts on Facebook and visualizing Twitter account connections.
Social media content analysis is a hot topic among startups. There are more and more services for searching for posts and people every year. But many of them either disappear quickly, are available in an unfinished state, or are expensive to use.
This material contains those few of them that allow you to quickly and free of charge get really useful or just interesting information.
1. Profile search
Search system snitch allows you to search for a person's profiles in four dozen services, including the websites of the world's leading universities and the US criminal database:

Unfortunately, some of the sites for which you can check the boxes no longer work. For example, Google Uncle Sam, closed 5 years ago. But despite this and other jambs, Snitch is a useful service that can significantly save time when searching for information about a person.
If for some service instead of blocks with search results a blank screen is displayed, then to view them you need to follow the link Open a new window:
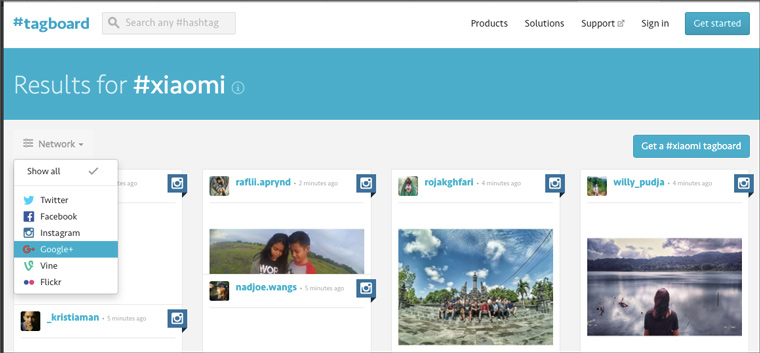
2. Search for hashtags
It is very easy to use. It is necessary to drive the desired hashtag into the search form and in a second a list of recent entries marked by it in six social networks will appear:
3. Analysis of recent tweets
The service allows you to get a list of the last hundred tweets containing the search word, hashtag or account name. And also to find out some analytical information about the people who made these tweets and the time of their creation:

Let's say you want to find out which user caused an unusually high number of clicks to an article from Twitter. We look at the last 100 tweets and see which of the people who mentioned the original concept has the most followers:

A large number of tweets are available to owners of a paid subscription for analysis:

4. Twitter account analysis
On the Mention app you can enter the account name and get information about it (who retweets most often, what hashtags it uses, etc.) in the form of a link diagram:

5. Search for tweets on the map
If you click anywhere on the map on , you can read the latest tweets made nearby:

6. The number of mentions in social networks
Sharedcount helps to evaluate the popularity of an article/site in social networks. You drive in the URL and in a couple of seconds there are statistics of mentions on Facebook, Google+, Pinterest, LinkedIn and Stumble Upon:

7. Search forums
boardreader is a search engine for forums and bulletin boards:
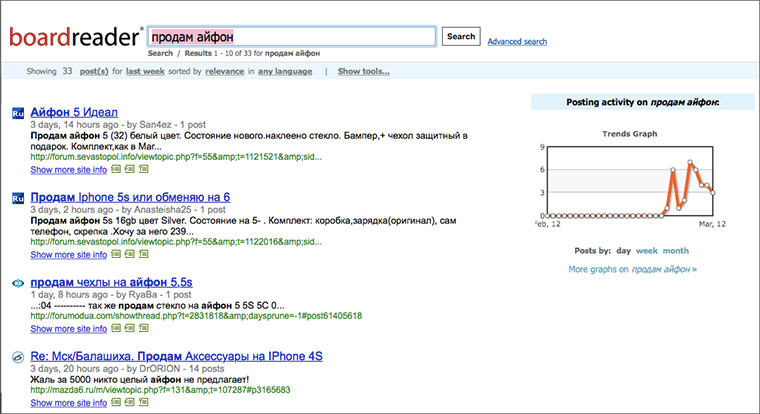

An assessment of the scale of the disaster showed that there are almost 4 responses on this portal per inhabitant of Russia.
8. We break through the login on social networks
Go to knowem.com and type in the person's nickname. In response, we receive information about which services it is registered on:

9. Determine the person's name by email
If you are still looking for people by entering their email addresses into Google, then you should give up this method. After all, there is pipl.com. You drive in an email (nickname) and get a list of profiles in social networks:

The information is not always accurate and complete, but the service is exceptionally useful.
That's all. It was worth talking about Socialmention (unfinished review analysis), Yomapic (search for photos from VK and Instagram on the map) and yandex.
By mid-2015, the global Internet network had already connected 3.2 billion users, that is, almost 43.8% of the world's population. For comparison: 15 years ago, only 6.5% of the population were Internet users, that is, the number of users increased by more than 6 times! But more impressive are not quantitative, but qualitative indicators of the expansion of the introduction of Internet technologies in various areas of human activity: from global communications of social networks to household Internet things. Mobile Internet provided an opportunity for users to be online outside the office and at home: on the road, outside the city in nature.
Currently, there are hundreds of systems for searching information on the Internet. The most popular of them are available to the vast majority of users because they are free and easy to use: Google, Yandex, Nigma, Yahoo!, Bing ..... More experienced users have "advanced search" interfaces, specialized "social network" searches , according to news flows and sale and purchase advertisements ... But all these wonderful search engines have a significant drawback, which I have already noted as an advantage above: they are free.
If investors invest billions of dollars in the development of search engines, then a quite relevant question arises: where do they earn money?
And they earn in particular on the fact that they provide user requests not only with the information that would be useful from the user's point of view, but with the information that the owners of search engines consider useful for the user. This is done by manipulating the order of issuing lists of answers to user search queries. Here and open advertising of certain Internet resources, and hidden juggling of the relevance of answers based on the commercial, political and ideological interests of the owners of search engines.
Therefore, among professional specialists in information search on the Internet, the problem of the pertinence of the results of search engines is very relevant.
Pertinence is the correspondence of the documents found by the information retrieval system to the information needs of the user, regardless of how completely and how accurately this information need is expressed in the text of the information request itself. This is the ratio of the amount of useful information to the total amount of information received. Roughly speaking, this is search efficiency.
Specialists who carry out a qualified search for information on the Internet need to make certain efforts to filter search results, filtering out unnecessary information "noise". And for this, professional-level search tools are used.
One of these professional systems is Russian program FileForFiles & SiteSputnik (SiteSputnik).
Developer Alexey Mylnikov from Volgograd.
"The FileForFiles & SiteSputnik program (SiteSputnik) is designed to organize and automate professional search, collection and monitoring of information posted on the Internet. Particular attention is paid to obtaining new information on topics of interest. Several information analysis functions have been implemented."
Monitoring and categorization of information flows
First, a few words about information flow monitoring, a special case of which is monitoring of media and social networks:
- the user indicates the Sources that may contain the required information, and the Rules for selecting this information;
- the program downloads fresh links from the Sources, frees their content from garbage and repetitions, and sorts them into Headings in accordance with the Rules.
To see live a simple but real monitoring process, which involves 6 sources and 4 headings:- open Demo version of the program;
- then, in the window that appears, click on the button jointly;
- and when SiteSputnik will execute this Project in real time, you:
- in the "Clean stream" list you will see all the new information from the Sources,
— in the "Post-request" section - only economic and financial news that satisfy the rule,
- in the Headings "About the President", "About the Prime Minister" and "Central Bank", - information related to the respective objects.
In real Projects, you can use almost any number of Sources and Headings.
You can create your first working Projects in a few hours, their improvement is in the process of operation.
The described information processing is available in the SiteSputnik Pro+News package and higher.
2. Simple and batch search, information collection
To get acquainted with the possibilities SiteSputnik Pro(basic version of the program package) :
- open Demo version of the program;
- enter your first request, for example, your full name, as I did:
and click on the button Search.
- The program (see the sign that SiteSputnik built) in a few seconds will interrogate 7 sources, will discover in them 24 search pages, find 227 relevant links remove redundant links and from the rest 156 unique links will list "Union".
Total: number of unique links - 156 , repeated links - 46 %.
Name
source
Ordered
pages
Downloaded
pages
Found
links
Time
search
efficiency
search
Links
New
efficiency
NewYandex 5 5 50 0:00:05 32% 0 0 5 5 44 0:00:03 28% 0 0 Yahoo 5 5 50 0:00:05 32% 0 0 Rambler 5 4 56 0:00:07 36% 0 0 MSN (Bing) 5 3 23 0:00:04 15% 0 0 Yandex.Blogs 5 1 1 0:00:01 1% 0 0 Google.Blogs 5 1 3 0:00:01 2% 0 0 Total: 35 24 227 0:00:26 — 0 0 - (! ) Repeat your request in a few hours or days, and you will see in a separate list only new links , which appeared in the output of Sources for this period of time. In the last two columns of the table, you can see how many new links each Source brought and its efficiency in terms of "novelty". When a query is executed multiple times, a list containing only new links , is created relative to all previous executions of this query. It would seem an elementary and necessary function, but the author is not aware of any program in which it is implemented.
- (!! ) The described features are supported not only for individual requests, but also for entire request packages :
The package you see consists of seven different queries that collect information about Vasily Shukshin from several Sources, including search engines, Wikipedia, exact search in Yandex news, metasearch, and search for mentions on TV and radio stations. To the script TV and Radio includes: Channel One, TV Russia, NTV, RBC TV, Ekho Moskvy, radio company Mayak, ... and other sources of information. Each Source has its own depth of search or viewing in pages. It is listed in the third column.
Batch search allows one-click comprehensive search collection of information on a given topic.
Separate list new links, on repeated executions of the package, will contain only references not found before.
Remember what and when you asked the Internet and what he answered you no need- everything is automatically saved in the libraries and databases of the program.
I repeat that the features described in this paragraph are fully included in the package. SiteSpunik Pro.
Read more in the instructions: SiteSputnik Pro for beginners.
3. Search objects and monitoring
Quite often, the User faces the following task. You need to find out what is on the Internet about a particular object: a person or a company. For example, when hiring a new employee or when a new counterparty appears, you always know the full name, company name, telephone numbers, TIN, PSRN or PSRNIP, you can also take ICQ, Skype and some other data. Further, using the call to the special function of the program SiteSputnik "Collection of information about the object" (equipment SiteSputnik Pro+Objects):You enter the data that you know, and with one click of the mouse, accurate And full search for links containing the given information. The search is performed on several search engines at once, using all the details at once, using several possible combinations of details at once: remember how you can write a phone number in different ways. After a certain period of time, without doing boring routine work, you will receive a list of links, cleared of repetitions and, most importantly, ordered by relevance to the object you are looking for. Relevance (significance) is achieved due to the fact that the first in the issuance of SiteSputnik will be those links on which the large quantity details specified by you, and not those that promoted the Webmaster's search engine results.
Important .
The SiteSputnik program is able to extract better than other programs real, but not official information about the Object. For example, in the official database mobile operator it can be written that the phone belongs to Vasily Terekhin, but in reality this phone has information that Alexander sold a Ford Focus car in 2013, which is additional information for reflection.Search monitoring .
Search monitoring means the following. If you want to track the appearance new links, by a given object or arbitrary batch of requests, then you just need to periodically repeat the corresponding search. Same as for a simple request, SiteSputnik program will create a "New" list, in which it will place only those links that were not found in any of the previous searches.Search monitoring interesting not only in itself. It may be involved in media monitoring, social networks and other news sources, which was mentioned above in paragraph 1. Unlike other programs in which it is possible to remove new information only from RSS feeds, the program SiteSputnik can be used for this in-site searches And search engines . Also possible emulation(self-creation) several RSS feeds from arbitrary pages, moreover, emulation of an RSS feed on a request and even a batch of requests.
- To get the most out of the program, use its main features, namely:
- request packages, packages with parameters, use Assembler (collector), the "Analytical Union" operation of the results of several tasks, if necessary, apply basic search functions on the invisible Internet;
- connect your sources to the information sources built into the program : other search engines and in-site searches, existing RSS feeds created by you own RSS feeds from arbitrary pages, apply the search for new sources;
- take advantage of the following options monitoring: Mass media, social networks and other sources, monitoring comments to news and messages, track the appearance of new information on existing pages;
- engage Categories , External Features, Task Scheduler, Mailing List, Multiple Computers, Project Instructor, Install alarm to notify about the occurrence of significant events, use the other functions listed below.
4. SiteSputnik program (SiteSputnik): options and features
- Program SiteSputnik constantly improving in the direction of: "I need to find everything and with a guarantee".
"Program for interrogating the Internet", is another definition of the User to assign the program to.BUT. Functions of search and collection of information.
. Request package - execution of several queries at once with the combination of search results or separately. When generating a combined result, re-found links are removed. More about packages - in the introduction to SiteSputnik, visually - in the video: a joint And separate execution of requests. There are no analogues in domestic and foreign developments.
. Packages with options. Any requests and packages of requests designed to solve standard search tasks, for example, search by phone, name or e-mail, - can be parameterized, saved and executed from a library of ready-made requests with substitution of the actual (required) parameter values. Each package with parameters is its own special advanced search form . It can use not one, but several search engines. It is possible to create forms that are very complex in their functional purpose. It is extremely important that forms can be created by the users themselves, without the participation of the author of the program or the programmer. It is extremely simple about this in the instructions, more details in a separate publication on the parameterization of the search and on the forum, clearly on the video: search for all number entry options at once mobile phone and by several options for writing the address Email. There are no analogues.
. assembler NEW- assembly of a search task from several ready-made : requests, request packages, and parameter packages. Packages may contain other packages in their text. The nesting depth of packages is unlimited. You can create several search tasks, for example, about several legal entities and individuals, and complete these tasks at the same time. More details on the forum and in a separate publication about Assembler, clearly on video. There are no analogues.
. Metasearch - execution of a specific query simultaneously for a given "depth" of the search for each of them. Metasearch is possible on built-in search engines, which include Yandex, Rambler, Google, Yahoo, MSN (Bing), Mail, Yandex and Google blogs, and on connected search tools. Working with several search engines looks like you are working with one search engine . Re-found links are removed. Visually metasearch on three connected social networks: VKontakte, Twitter and Youtube, is shown on video.
. Site metasearch - unification of site search in Google, Yahoo, Yandex, MSN (Bing). Clearly on video.
. Metasearch in office documents - combining search in PDF, XLS, DOC, RTF, PPT, FLASH files in Google, Yahoo, Yandex, MSN (Bing). You can choose any combination of file formats.
. Metasearch cache copies links in Yandex, Google, Yahoo, MSN (Bing). A list is compiled, in each paragraph of which all snippets found for each link by each search engine are collected. There are no analogues.
. Deep Search for Yandex, Google and Rambler, allows you to combine into one list all links from the regular search and all links, respectively, from the "More from the site", "Additional results from the site" and "Search on the site (Total...)" lists. Read more about deep search on the forum. There are no analogues.
. Accurate and complete search . This means the following. On the one hand, each query can be executed on that and only that source, in whose query language it is written. This exact search. On the other hand, there can be an arbitrary number of such requests and sources. This provides full search. More details in a separate post on procedural search. There are no analogues.
. Searching the Invisible Web .
It includes the following basic features:
B. Information monitoring functions.A special package of requests that can be improved by the User,
- search for invisible links using a spider (spider),
- search for invisible links in the vicinity of a visible link or folder by "image and likeness",
- special searches for open folders,
- search for invisible links and folders with standard names using special dictionaries,
- use of your own searches built into the sites.More details in a separate publication on SiteSputnik Invisible. The basic functions are "well known in narrow circles", but the way they are used has no analogues. The essence of this method is to build a site map visible from the Internet (in other words, the materialization of the visible Internet), and only on the basis of visible links and relative to them, the search for invisible links. Search for already visible links by "invisible" methods is not carried out.
. Monitoring for appearing on the internet new links on a given topic. Monitor appearance new links can be using whole request packages , which involve any of the search methods mentioned above, and not individual first pages of search engines. Union and intersection implemented new links from several separate searches. More details in the monitoring publication (see § 1) and on the forum . There are no analogues.
. Collective information processing . Creation corporate or professional network for the collective collection, monitoring and analysis of information. The participants and creators of such a network are employees of the corporation, members of the professional community or interest groups. The geographical location of the participants does not matter. More details in a separate publication on the organization of a network of collective collection, monitoring and analysis of information.
. Monitoring links (web pages) to detect changes in their content (content). Beta version. Found changes are highlighted with color and special signs. More details in a separate monitoring publication (see § 2 and 3).
IN. Information analysis functions.
. Category of materials already described above. More details - in a separate publication about Rubrics. Rubrics hit rules allow you to specify keywords and the distance between them, set logical "AND", "OR" and "NOT", apply a multi-level bracket structure and dictionaries (insert files) to which you can apply logical operations.
. VF technology - almost arbitrary extension of the possibility of categorizing materials through the implementation of external functions that are organically built into the Rules for getting into Rubrics and can be implemented by the programmer independently without the participation of the author of the program.
. Numerical analysis occupancy Rubrics, installation signaling and notification of the occurrence of significant events by highlighting Rubrics and/or sending an alarm report by e-mail.
. actual relevance. There is an option to arrange the links in order close to significance these links in relation to the problem being solved, bypassing the tricks of webmasters who use various methods to increase the ranking of sites in search engines. This is achieved by analyzing the results of several "diverse" queries on a given topic. Calculated, in the truest sense of the word, links containing maximum required information . Read more in the description of how to find the best supplier and on the forum. There are no analogues.
. Computing Object Relationships - search for links, resources (sites), folders and domains that simultaneously mention objects. The most common objects are people and firms. To search for connections, all the program tools mentioned on this page can be used. SiteSputnik which significantly increases the efficiency of your work. The operation is performed on any number of objects. More details in the introduction to the program, as well as in the description of the new feature "objects and their relationships". There are no analogues.
. Formation, association and intersection of information flows on a variety of topics, matching streams. More details in a separate threading post.
. Building web maps sites, resources, folders and searched objects based on the links found on the Internet using Google, Yahoo, Yandex, MSN (Bing) and Altavista links belonging to the site. Experts can find out if you can see "extra" information from the Internet on their sites, as well as to investigate the sites of competitors on this subject. The web sitemap is materialization of the visible internet . More details in a separate publication on building web maps, clearly on video. There are no analogues.
. Search for new sources of information on a given topic, which can then be applied to track the emergence of new relevant information. Read more at.
G. Service functions.
. Task Scheduler provides work Scheduled: performs the specified functions of the program at the specified time. Read more in a separate post about Scheduler.
. Project Instructor NEW is an assistant creation and maintenance Projects on search, collection, monitoring and analysis of information (categorization and signaling). Read more on the forum.
. Automatic archiving. IN databases all the results of your work are automatically stored, namely: requests, request packages, search and monitoring protocols, any other functions listed above and the results of their execution. Can structure work on themes and sub-themes.
. Database includes sorts, simple searches, and arbitrary searches by SQL query. For the latter, there is a wizard for compiling SQL queries. Using these tools, you can find and familiarize yourself with the work that you did yesterday, last month, a year ago, define a topic as a search criterion, or set another search criterion for the content of the database.
. Technical limitations search engines. Some restrictions, such as the length of the query string, can be overcome. The execution of not one, but several queries with the combination of search results or separately is provided. You can read about the way to overcome the violation of the law of additivity for the main search engines. For one word or one phrase, taken in quotation marks, a case-sensitive search is implemented in search engines, in particular, an abbreviation search.
built-in browser . Navigator by pages. Multicolor marker to highlight key and arbitrary words. Bilisting and N-listing from generated documents.
. Unloading feeds into a tabular view focused on import in Excel, MySQL, Access, Kronos and other Applications.
5. Installing and running the Program, computer requirements.
To install and run the program:
- Download the file, copy the FileForFiles folder from it to your HDD, for example, on D:\;
- Demo version of the program will be installed and will open.
The program will work on any computer that has Windows of any version installed.Professional search on the Internet requires specialized software, as well as specialized search engines and search services.
PROGRAMS
http://dr-watson.wix.com/home - a program designed to study arrays of textual information in order to identify entities and relationships between them. The result of the work is a report on the object under study.
http://www.fmsasg.com/ - Sentinel Vizualizer is one of the world's best connection and relationship visualization software. The company completely Russified its products and connected a hotline in Russian.
http://www.newprosoft.com/ - "Web Content Extractor" is the most powerful, easy to use web site data extraction software. It also has an efficient Visual Web spider.
SiteSputnik – a software package that has no analogues in the world, which allows you to search and process its results in the Visible and Invisible Internet, using all the search engines necessary for the user.
WebSite-Watcher - allows you to monitor web pages, including password-protected ones, monitor forums, RSS feeds, newsgroups, local files. It has a powerful filter system. Monitoring is automatic and delivered in a user-friendly way. The program with advanced features costs 50 euros. Constantly updated.
http://www.scribd.com/ is the most popular platform in the world and increasingly used in Russia for hosting various kinds of documents, books, etc. for free access with a very convenient search engine for names, topics, etc.
http://www.atlasti.com/ - is the most powerful and effective tool available for individual users, small and even medium-sized businesses for qualitative information analysis. The program is multifunctional and therefore useful. It combines the possibilities of creating a single information environment for working with various text, spreadsheet, audio and video files as a whole, as well as tools for qualitative analysis and visualization.
Ashampoo ClipFinder HD - An increasing proportion of the information flow is video. Accordingly, competitive scouts need tools to work with this format. One of these products is the free utility. It allows you to search for videos by specified criteria on video file storages such as YouTube. The program is easy to use, displays all search results on one page with detailed information, titles, duration, time when the video was uploaded to storage, etc. There is a Russian interface.
http://www.advego.ru/plagiatus/ - the program is made by seo optimizers, but it is quite suitable as an Internet intelligence tool. Plagiarism shows the degree of uniqueness of the text, the sources of the text, the percentage of text matching. The program also checks the uniqueness of the specified URL. The program is free.
http://neiron.ru/toolbar/ - includes an add-on for combining Google search and Yandex, and also allows for competitive analysis based on evaluating the effectiveness of sites and contextual advertising. Implemented as a plugin for FF and GC.
http://web-data-extractor.net/ is a universal solution for obtaining any data available on the Internet. Setting up cutting data from any page is done in a few mouse clicks. You just need to select the data area that you want to save and Datacol will select the formula for cutting this block.
CaptureSaver is a professional internet research tool. Just an indispensable working program that allows you to capture, store and export any information on the Internet, including not only web pages, blogs, but also RSS news, email, images and much more. It has the widest functionality, an intuitive interface and a ridiculous price.
http://www.orbiscope.net/en/software.html - web monitoring system at more than affordable prices.
http://www.kbcrawl.co.uk/ - software for work, including in the "Invisible Internet".
http://www.copernic.com/en/products/agent/index.html - the program allows you to search using more than 90 search engines, more than 10 parameters. Allows you to merge results, eliminate duplicates, block broken links, show the most relevant results. Comes in free, personal and professional versions. Used by more than 20 million users.
Maltego is a fundamentally new software that allows you to establish the relationship of subjects, events and objects in real life and on the Internet.
SERVICES
new is a web browser with dozens of preinstalled tools for OSINT.
is an effective search aggregator for finding people in the main Russian in social networks.
https://hunter.io/ is an efficient email detection and verification service.
https://www.whatruns.com/ is an easy to use yet effective scanner to discover what is working and not working on a website and what are the security holes. Also implemented as a plugin for Chrom.
https://www.crayon.co/ is an American low-cost market and competitive intelligence platform on the Internet.
http://www.cs.cornell.edu/~bwong/octant/ - host locator.
https://iplogger.ru/ - a simple and convenient service for determining someone else's IP.
http://linkurio.us/ is a powerful new product for economic security workers and corruption investigators. Processes and visualizes huge arrays of unstructured information from financial sources.
http://www.intelsuite.com/en is an English-language online platform for competitive intelligence and monitoring.
http://yewno.com/about/ is the first operating system for translating information into knowledge and visualizing unstructured information. Currently supports English, French, German, Spanish and Portuguese.
https://start.avalancheonline.ru/landing/?next=%2F - forecasting and analytical services of Andrey Masalovich.
https://www.outwit.com/products/hub/ - a complete set of stand-alone programs for professional work on the web 1.
https://github.com/search?q=user%3Acmlh+maltego - extensions for Maltego.
http://www.whoishostingthis.com/ - search engine for hosting, IP addresses, etc.
http://appfollow.ru/ - analysis of applications based on reviews, ASO optimization, positions in tops and search results for the App Store, Google Play and Windows Phone Store.
http://spiraldb.com/ is a service implemented as a plugin for Chrom that allows you to get a lot of valuable information about any electronic resource.
https://millie.northernlight.com/dashboard.php?id=93 - a free service that collects and structures key information on industries and companies. It is possible to use information panels based on text analysis.
http://byratino.info/ - collection of factual data from publicly available sources on the Internet.
http://www.datafox.co/ - CI platform that collects and analyzes information on companies of interest to customers. There is a demo.
https://unwiredlabs.com/home - a specialized application with an API for searching by geolocation of any device connected to the Internet.
http://visualping.io/ is a service for monitoring sites and, first of all, the photos and images on them. Even if the photo appeared for a second, it will be in e-mail subscriber. Has a plugin for Google Chrome.
http://spyonweb.com/ is a research tool that allows you to carry out a deep analysis of any Internet resource.
http://bigvisor.ru/ - the service allows you to track advertising campaigns for certain segments of goods and services, or for specific organizations.
http://www.itsec.pro/2013/09/microsoft-word.html - Artem Ageev's instructions for using Windows programs for the needs of competitive intelligence.
http://granoproject.org/ is an open source tool for researchers who trace networks of connections between persons and organizations in politics, economics, crime, and more. Allows you to connect, analyze and visualize information obtained from various sources, as well as show significant relationships.
http://imgops.com/ is a service for extracting metadata from graphic files and working with them.
http://sergeybelove.ru/tools/one-button-scan/ - a small online scanner for checking security holes in websites and other resources.
http://isce-library.net/epi.aspx - search service for primary sources by a fragment of text in English
https://www.rivaliq.com/ is an effective tool for conducting competitive intelligence in Western, primarily European and American markets for goods and services.
http://watchthatpage.com/ is a service that allows you to automatically collect new information from monitored resources on the Internet. Service services are free.
http://falcon.io/ is a kind of Rapportive for the Web. It is not a replacement for Rapportive, but provides additional tools. Unlike Rapportive, it gives a general profile of a person, as if glued together from data from social networks and mentions in web.http://watchthatpage.com/ - a service that allows you to automatically collect new information from monitored resources on the Internet. Service services are free.
https://addons.mozilla.org/en/firefox/addon/update-scanner/ is an addon for Firefox. Keeps track of web page updates. Useful for websites that don't have news feeds (Atom or RSS).
http://agregator.pro/ is an aggregator of news and media portals. Used by marketers, analysts, etc. to analyze news flows on certain topics.
http://price.apishops.com/ is an automated web service for monitoring prices for selected product groups, specific online stores and other parameters.
http://www.la0.ru/ is a convenient and relevant service for analyzing links and backlinks to an Internet resource.
www.recordedfuture.com is a powerful data analysis and visualization tool implemented as an online service based on cloud computing.
http://advse.ru/ is a service under the slogan “Learn everything about your competitors”. Allows you to get competitors' websites in accordance with search queries, analyze competitors' advertising campaigns in Google and Yandex.
http://spyonweb.com/ – the service allows you to identify sites with the same characteristics, including those using the same Google Analytics statistics service identifiers, IP addresses, etc.
http://www.connotate.com/solutions - a line of products for competitive intelligence, information flow management and transformation of information into information assets. It includes both complex platforms and simple cheap services that allow you to effectively monitor along with information compression and getting only the results you need.
http://www.clearci.com/ is a competitive intelligence platform for businesses of all sizes from startups and small companies to Fortune 500 companies. Designed as saas.
http://startingpage.com/ is a Google add-on that allows you to search Google without fixing your IP address. Fully supports all Google search features, including Russian.
http://newspapermap.com/ is a unique service that is very useful for a competitive intelligence officer. Connects geolocation with an online media search engine. Those. you choose the region or even the city or language you are interested in, see the place and the list of online versions of newspapers and magazines on the map, click on the appropriate button and read. Supports Russian language, very user-friendly interface.
http://infostream.com.ua/ is a very convenient, distinguished by first-class selection, quite accessible for any wallet, the Infostream news monitoring system from one of the classics of Internet search D.V. Lande.
http://www.instapaper.com/ is a very simple and effective tool for saving the necessary web pages. Can be used on computers, iPhones, iPads, etc.
http://screen-scraper.com/ - allows you to automatically extract all information from web pages, download the vast majority of file formats, automatically enter data into various forms. Downloaded files and pages are stored in databases and perform many other extremely useful functions. Works under all major platforms, has a fully functional free and very powerful professional versions.
http://www.mozenda.com/ - having several tariff plans and available even for small businesses, a web service for multifunctional web monitoring and delivery from selected sites of the information necessary for the user.
http://www.recipdonor.com/ - the service allows you to automatically monitor everything that happens on the sites of competitors.
http://www.spyfu.com/ - and this is if you have foreign competitors.
www.webground.su is a service for monitoring the Runet, created by Internet search professionals, which includes all the main providers of information, news, etc., and is capable of individual monitoring settings for the needs of the user.
SEARCH ENGINES
https://www .idmarch .org/ is the best search engine for the world archive of pdf documents in terms of quality. Currently, more than 18 million pdf documents have been indexed, ranging from books to secret reports.
http://www.marketvisual.com/ is a unique search engine that allows you to search for owners and top management by full name, company name, position, or a combination of them. IN search results contains not only the desired objects, but also their relationships. Designed primarily for English-speaking countries.
http://worldc.am/ is a free-access photo search engine with reference to geolocation.
https://app.echosec.net/ is a public domain search engine that describes itself as the most advanced analytics tool for law enforcement and security and intelligence professionals. Allows you to search for photos posted on various sites, social platforms and social networks in relation to specific geolocation coordinates. There are currently seven data sources connected. By the end of the year, their number will be more than 450. Thanks to Dementy for the tip.
http://www.quandl.com/ is a search engine for seven million financial, economic and social databases.
http://bitzakaz.ru/ - search engine for tenders and government orders with additional paid features
Website-Finder - makes it possible to find sites that are poorly indexed by Google. The only limitation is that it only searches 30 websites for each keyword. The program is easy to use.
http://www.dtsearch.com/ is the most powerful search engine that allows you to process terabytes of text. Works on desktop, web and intranet. Supports both static and dynamic data. Allows you to search in all MS Office programs. The search is conducted by phrases, words, tags, indexes and much more. The only federated search engine available. It has both paid and free versions.
http://www.strategator.com/ - searches, filters and aggregates company information from tens of thousands of web sources. Searches for the USA, Great Britain, the main countries of the EEC. It is highly relevant, user-friendly, has free and paid options ($14 per month).
http://www.shodanhq.com/ is an unusual search engine. Immediately after the appearance, he received the nickname "Google for hackers". It does not look for pages, but determines IP addresses, types of routers, computers, servers and workstations located at a particular address, traces chains of DNS servers and allows you to implement many other interesting functions for competitive intelligence.
http://search.usa.gov/ is a search engine for websites and open databases of all US government agencies. The databases contain a lot of practical useful information, including for use in our country.
http://visual.ly/ – Visualization is increasingly being used to present data. It is the first infographic search engine on the web. Along with the search engine, the portal has powerful data visualization tools that do not require programming skills.
http://go.mail.ru/realtime - search for discussions of topics, events, objects, subjects in real or custom time. The previously highly criticized search in Mail.ru works very efficiently and gives interesting, relevant results.
Zanran is the first and only search engine for data that extracts data from PDF files, EXCEL tables, data on HTML pages.
http://www.ciradar.com/Competitive-Analysis.aspx is one of the world's best search engines for competitive intelligence on the deep web. Extracts almost all kinds of files in all formats on the topic of interest. Implemented as a web service. The prices are more than reasonable.
http://public.ru/ - Efficient Search and professional information analysis, media archive since 1990. The online media library offers a wide range of information services: from access to electronic archives of Russian-language media publications and ready-made thematic press reviews to individual monitoring and exclusive analytical studies based on press materials.
Cluuz is a young search engine with ample opportunities for competitive intelligence, especially on the English-speaking Internet. Allows not only to find, but also to visualize, establish links between people, companies, domains, e-mail, addresses, etc.
www.wolframalpha.com is the search engine of tomorrow. For a search query, it issues statistical and factual information available on the request object, including visualized information.
www.ist-budget.ru - universal search in databases of public procurement, tenders, auctions, etc.
