Collection of semantics. How and for what can you use the semantic core of your competitors? Step #3 - Collecting the exact frequency for the keys
Today, any business represented on the Internet (and this is, in fact, any company or organization that does not want to lose its audience of customers “online”) pays considerable attention to search engine optimization. This is the right approach that can help significantly reduce promotion costs, reduce advertising costs and, when the desired effect occurs, create a new source of customers for the business. Among the tools with which promotion is carried out is the compilation of a semantic core. We will tell you what it is and how it works in this article.
What is “semantics”
So, we will start with a general idea of what the concept of “collecting semantics” is and means. On various Internet sites dedicated to search engine optimization and website promotion, it is described that the semantic core can be called a list of words and phrases that can fully describe its topic, field of activity and focus. Depending on how large-scale a given project is, it may have a large (and not so large) semantic core.
It is believed that the task of collecting semantics is key if you want to start promoting your resource in search engines and want to receive “live” search traffic. Therefore, there is no doubt that this should be taken with complete seriousness and responsibility. Often, a correctly assembled semantic core is a significant contribution to the further optimization of your project, to improving its position in search engines and the growth of indicators such as popularity, traffic and others.
Semantics in advertising campaigns
In fact, compiling a list of keywords that best describe your project is important not only if you are engaged in search engine optimization. When working with systems such as Yandex.Direct and Google Adwords, it is equally important to carefully select those “keywords” that will make it possible to get the most interested customers in your niche.

For advertising, such thematic words (their selection) are also important for the reason that with their help you can find more accessible traffic from your category. For example, this is relevant if your competitors work only on expensive keywords, and you “bypass” these niches and promote where there is traffic that is secondary to your project, but is nevertheless interested in your project.
How to collect semantics automatically?
In fact, today there are developed services that allow you to create a semantic core for your project in a matter of minutes. This, in particular, is a project for automatic promotion of Rookee. The procedure for working with it is described in a nutshell: you need to go to the appropriate page of the system, where it is proposed to collect all the data about the keywords of your site. Next, you need to enter the address of the resource that interests you as an object for compiling the semantic core.
The service automatically analyzes the content of your project, determines its keywords, and receives the most definable phrases and words that the project contains. Due to this, a list of those words and phrases that can be called the “base” of your site is formed for you. And, in truth, it is easiest to assemble semantics this way; Anyone can do this. Moreover, the Rookee system, by analyzing suitable keywords, will also tell you the cost of promotion for a particular keyword, and will also make a forecast as to how much search traffic you can get if you promote these queries.
Manual compilation

If we talk about selecting keywords automatically, there’s really nothing to talk about here for a long time: you simply use the developments of a ready-made service that suggests keywords to you based on the content of your site. In fact, not in all cases the result of this approach will suit you 100%. Therefore, we recommend also turning to the manual option. We will also talk about how to collect semantics for a page with your own hands in this article. However, before that you need to leave a couple of notes. In particular, you should understand that manually collecting keywords will take you longer than working with an automatic service; but at the same time, you will be able to identify higher priority requests for yourself, based not on the cost or effectiveness of their promotion, but focusing primarily on the specifics of your company’s work, its vector and the features of the services provided.
Defining the topic
First of all, when talking about how to collect semantics for a page manually, you need to pay attention to the topic of the company, its field of activity. Let's give a simple example: if your site represents a company selling spare parts, then the basis of its semantics will, of course, be queries that have the highest frequency of use (something like “auto parts for Ford”).
As search engine optimization experts note, you shouldn’t be afraid to use high-frequency queries at this stage. Many optimizers mistakenly believe that there is a lot of competition in the fight for these frequently used, and therefore more promising, queries. In reality, this is not always the case, since the return from a visitor who comes with a specific request like “buy a battery for a Ford in Moscow” will often be much higher than from a person looking for some general information about batteries.
It is also important to pay attention to some specific points related to the operation of your business. For example, if your company is represented in the field of wholesale sales, the semantic core should display keywords such as “wholesale”, “buy in bulk” and so on. After all, a user who wants to purchase your product or service in a retail version will simply be uninteresting to you.
We focus on the visitor

The next stage of our work is to focus on what the user is looking for. If you want to know how to build semantics for a page based on what a visitor is searching for, you need to look at the key queries they're making. For this, there are services such as “Yandex.Wordstat” and Google Keyword External Tool. These projects serve as a guide for webmasters to search for Internet traffic and provide an opportunity to identify interesting niches for their projects.
They work very simply: you need to “drive” a search query into the appropriate form, on the basis of which you will search for relevant, more specific ones. Thus, here you will need those high-frequency keywords that were installed in the previous step.
Filtration
If you want to collect semantics for SEO, the most effective approach for you will be to further filter out “extra” queries that turn out to be inappropriate for your project. These, in particular, include some keywords that are relevant to your semantic core from the point of view of morphology, but differ in their essence. This should also include keywords that will not properly characterize your project or will do it incorrectly.

Therefore, before collecting the semantics of keywords, it will be necessary to get rid of inappropriate ones. This is done very simply: from the entire list of keywords compiled for your project, you need to select those that are unnecessary or inappropriate for the site and simply delete them. In the process of such filtering, you will establish the most suitable queries that you will focus on in the future.
In addition to the semantic analysis of the presented keywords, due attention should also be paid to filtering them by the number of requests.
This can be done using the same Google Keyword Tool and Yandex.Wordstat. By typing a request into the search form, you will not only receive additional keywords, but also find out how many times a particular request is made during the month. This way you will see the approximate amount of search traffic that can be obtained through promotion for these keys. Most of all at this stage we are interested in abandoning little-used, unpopular and simply low-frequency queries, promotion for which will be an extra expense for us.
Distribution of requests across pages
Once you have received a list of the most suitable keywords for your project, you need to start comparing these queries with the pages of your site that will be promoted on them. The most important thing here is to determine which page is most relevant to a particular request. Moreover, adjustments should be made to the link weight inherent in a particular page. Let's say the ratio is approximately this: the more competitive the request, the more cited the page should be selected for it. This means that when working with the most competitive ones, we should use the main one, and for those with less competition, pages of the third nesting level are quite suitable, and so on.

Competitor analysis
Don’t forget that you can always “peek” at how sites that are in the “top” positions of search engines for your key queries are being promoted. However, before collecting the semantics of competitors, it is necessary to decide which sites we can include in this list. It will not always include resources belonging to your business competitors.
Perhaps, from the point of view of search engines, these companies are engaged in promotion for other queries, so we recommend paying attention to such a component as morphology. Just enter queries from your semantic core into the search form - and you will see your competitors in the search results. Next, you just need to analyze them: look at the parameters of the domain names of these sites, collect semantics. What kind of procedure this is, and how easy it is to implement it using automated systems, we have already described above.
In addition to everything that has already been described above, I would also like to present some general tips that experienced optimizers give. The first is the need to deal with a combination of high- and low-frequency queries. If you only target one category of these, your promotion campaign may end up being a failure. If you choose only “high-frequency” ones, they will not give you the targeted visitors who are looking for something specific. On the other hand, low-frequency queries will not give you the required amount of traffic.
You already know how to collect semantics. Wordstat and Google Keyword Tool will help you determine which words are being searched for along with your keywords. However, do not forget about associative words and typos. These categories of queries can be very profitable if you use them in your promotion. Both the first and the second we can get a certain amount of traffic; and if the request is low-competitive, but targeted for us, such traffic will also be as accessible as possible.
Some users often have a question: how to collect semantics for Google/Yandex? This means that optimizers focus on a specific search engine when promoting their project. In fact, this approach is quite justified, but there are no significant differences in it. Yes, each of the search engines works with its own algorithms for filtering and searching for content, but it is quite difficult to guess where the site will be ranked higher. You can only find some general recommendations on what should be used if you are working with a particular software, but there are no universal rules for this (especially in a proven and publicly available form).
Compiling semantics for an advertising campaign
You may have a question about how to collect semantics for Direct? We answer: in general, the procedure corresponds to that described above. You need to decide: what queries are relevant to your site, which pages will interest the user most (and for which key queries), promotion by which keys will be the most profitable for you, and so on.

The specificity of how to collect semantics for Direct (or any other advertising aggregator) is that you need to categorically refuse non-topic traffic, since the cost of a click is much higher than in the case of search engine optimization. For this purpose, “stop words” (or “negative words”) are used. To understand how to assemble a semantic core with negative keywords, you need more in-depth knowledge. In this case, we are talking about words that can bring traffic that is not of interest to your site. Often these words can be “free”, for example, when we are talking about an online store, in which a priori nothing can be free.
Try to create a semantic core for your website yourself, and you will see that there is nothing complicated here.
First of all, let's figure out what the semantic core of a competitor's website is, how it is obtained and what it consists of. This understanding will allow us to make future decisions regarding the suitability of this core for various SEO tasks.
Semantics visible and actual
When a webmaster creates a website, he puts certain information into it and publishes documents tailored to certain keywords. Thus, it turns out that all the keywords of the competitor’s site, for which documents were created on this site, are the semantic core of the site. This is the actual semantics of the site.
The site has been created, begins to rank and appear in search engine results for a number of queries. For some requests, the site will not be able to be promoted; for them, the site will not be shown in the search results - let’s assume that they were incorrect. Some site pages do not appear in the search results - they are excluded by the search engine for one reason or another. Thus, out of all the actual semantics (incorporated into the site by the optimizer), the search engine ranks the site only for a certain part of the queries that it considered relevant. This is the visible semantics of the site.
The higher the proportion of visible queries in relation to actual ones, the higher the quality of the site.
How services receive the semantics of competitors
Most services that allow you to determine the keywords of competitors’ sites work according to the following principle:
A database of popular queries is compiled;
For each phrase, from 1 to 10 search results pages (SERP) are collected;
The collection of search results for all phrases is repeated once a week/month/year.
This leads to the following restrictions:
Services show only the visible part of competitors' keywords;
The services store a snapshot of the results at the time of collecting positions for all requests from the database;
Services know visibility only for those phrases that are in the database.
What conclusions follow from this?
To assess the “freshness” of a competitor’s semantics, you need to know when the positions were collected ();
Some requests for which the site is promoted may not be visible to us, because... the pages may not be in the index yet, or the PS has excluded pages from ranking for one reason or another (bad behavioral factors, malicious code, low page loading speed, etc.). Those. in fact, there are pages on the site, but we won’t see them in the search results;
Most often, we do not know what key phrases the service base consists of, which it uses to collect search engine results.
We do not see the true, actual semantic core of the site, for which the site was created by the owner, but only that fragment of the core that the search engine / service is currently showing us
What conclusion can we draw based on the above?
Competitors' keywords collected using services will never reflect the full semantics that are relevant at the moment;
Semantics of competitors collected using services can only serve as an auxiliary tool for expanding the existing semantic core, or help conduct analysis (competitor analytics);
Services that have a large database from which they collect search results will never be able to provide “fresh” / relevant semantics, because The more phrases and deeper the collection, the longer this process takes. While the results were collected at the beginning of the base, the results at the end of the base were outdated;
The services do not say how often they update their own keyword databases, which they use to analyze queries from competitors’ sites. Thus, we never reliably know how relevant the semantics are in front of us: we don’t know the “freshness” of the service base, we don’t know the date of collection, we don’t know the relationship between actual and visible semantics;
A significant advantage is that we immediately receive a large cluster of search queries from our main competitors and can integrate some of these queries into our core, supplementing it, thereby increasing its completeness.
In what cases will it be useful to use competitor semantics?
Launching a new project
We are planning the launch of a new project and collecting semantics for it from scratch. In the process of collecting keywords, we upload competitors’ keywords and queries that are suitable for our topic. Here it is important to take into account that not all semantics of a competitor may suit us. For example, if we are making a niche site, and the search results contain portals for which the semantic core can be huge, then we cannot just copy all the queries from it into ours.

Extending semantics for an existing project
We already have a website that we want to develop. The semantics for it were collected a long time ago and not optimally. Now we want to resume work on the site, create new sections, expand the range, or simply add new articles to attract additional traffic. However, there is a small catch - we don't know where to start. In this case, we can use services (about them below) and collect keywords from competitors’ sites.
How to extract competitor semantics as efficiently as possible?
You need to follow a few simple rules. First of all, we should look at the percentage of keyword overlaps between our site and donor sites. If we don’t have a website yet, then we take any competitor we like, open his website, analyze it, and if we like it, we take his website as a standard. Further, the entire assessment is based on the percentage of intersections by keys between the standard and donors. The easiest way is to download a list of all competitor sites from the services and sort them by the percentage of intersections. Next, we pump out the kernels of the first 3-5 competitors into Excel or Key Collector, whichever is more convenient, and move on to the stage of expanding the kernel. Secondly, you shouldn’t take the semantics of portals, even if our site has a lot of overlap with them. Each donor site must be checked visually.
Of all potential donor competitors, we select those that are closest to us in topic and have the maximum number of intersections between key phrases
Buying a website for development or resale
Let’s imagine a situation where we decided to buy a website in some niche and want to understand the development potential of this website. The easiest option would be to find out the semantic core of this site - to evaluate the current coverage of the topic in comparison with competitors. For ease of comparison, we can take the strongest competitor in the niche as a reference (maximum reach) and compare its visibility indicators with the visibility indicators of the site of the candidate for purchase. If we see that the site lags behind the leader by more than half, then this is a good indicator that the site has significant untapped potential for building up and expanding semantics and, as a result, significant growth in traffic.
IMPORTANT: In this analysis, we look only at niche competitors, we ignore portals
Where do you get competitors' semantics from?
Free tools
Update as of March 27, 2017: Since March 28, 2017 Free access to applications of the analytical platform Megaindex has ceased. The service has switched to a paid subscription.
Paid services
1. Megaindex Premium Analytics
The "Site Visibility" module of the Megaindex platform gives us a fairly extensive set of tools for obtaining competitors' key phrases: you can view and download the key phrases by which the site is ranked; find sites with similar semantics that can also be used as donors. The only drawback is that there is no way to sort lists on the fly; you will have to copy everything into Excel first and sort it there.

Brief summary of the service
2.Keys.so
The keys.so service was created as a tool for analyzing the semantics of competitors. It is necessary to enter the url of the site we are interested in, select donors by the number of common keys, analyze their sites and download the keys. Everything is done quickly and without unnecessary movements. Nice, fresh interface, only the necessary information. Disadvantages: database size, visibility update frequency. rather has a marketing function, because when adding to the kernel, it will still need to be rechecked.
Brief summary of the service

2. Spywords.ru
In addition to visibility analysis, the spywords.ru service provides statistics on ads in direct messages. The interface is a little overloaded, but if you look at it, the service generally solves its problem. You can analyze competitors’ websites, look at intersections in the semantic core, and download phrases used by competitors to promote themselves. The disadvantages include a rather weak database - only 23 million keywords. We conducted a full review of the service.
Brief summary of the service

Results
Thanks to the services, obtaining the semantic core of competitors’ websites has become less difficult. The only question is what to do with this kernel later. Key tips:
- The more phrases in the service database, the higher the chance of getting a more complete core. The other side of the coin is the freshness of the data.
We only take sites with similar topics as donors (the higher the percentage of intersections, the better);
We avoid portals so as not to get bogged down when adding the semantics of a competitor to our core (instead of an addition you get an extension :)). And, as we know, you can expand endlessly!
If you decide to buy a site, we look at its current visibility in the PS and compare it with leaders in the topic to understand its development potential;
We use competitor semantics only as a supplement to an already prepared core;
We have already told you more than once how you can create a semantic core for a website yourself and even wrote a book (by the way, you can download it completely free). Before trying to collect keywords using the services discussed in this article, I recommend reading the book to understand the basics.
The process of collecting semantics is very labor-intensive, requiring a lot of time, especially for beginners.
There are many specialized services and programs for compiling a semantic core. The most popular: Yandex.Wordstat and Google KeywordPlanner, Key Collector, Slovoeb, Megaindex.com, SEMRush, Just Magic, Topvisor and others.
Many of these products are paid, and each has its own advantages and disadvantages. Below we will look in detail at 2 assistants for collecting site semantics - one is paid, the other is free.
Rush Analytics - an online service for creating a semantic core
Allows you to automate all routine processes when collecting semantics: from key selection to clustering.
Pros:
- No software installation required.
- Clear and simple interface.
- Availability of guidelines for using the service and tips at each stage.
- Clustering reports have a lot of useful data that you can use to create content.
- You can expand the semantic core using the Search Suggestions tool.
Minuses:
The downside is that this is a completely paid service. Only upon registration you will receive a bonus of 200 rubles. If you have a large amount of work, it will cost you a lot. For example, clustering one key query costs 50 kopecks.
Collecting keywords
After a simple registration, 4 tools will be available for working with keywords: “Wordstat”, “Hint Collection”, “Clustering” and “Keyword Checker”.
Now you can start collecting keywords; to do this you need to create a new project:
In the tab that opens, indicate the project name and region:

The next step is Collection Settings. Here you need to choose how the words will be collected:
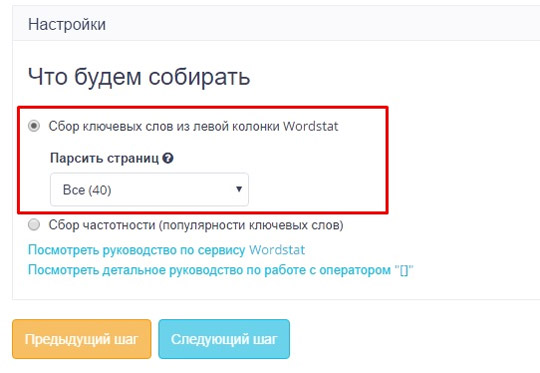
For work, we will choose the first option: collecting keywords from the left column of Wordstat.
Third step – Keywords and price. We indicate the base keywords of the site either in a list or upload a file.
For example, we have a website about renting special equipment. We enter the main keys “special equipment rental”, “crane rental”, “crane services”. This will be enough to collect semantics.

We also indicate stop words. They will help you filter your list and save time and money. There is a convenient function “Stop words by topic”.
For our site we will add the stop words “agreement”, “work”.
After some time our project will be ready:

Now you can download the file in xlsx format:

We received a fairly large list of keywords (1084 words). Some of them are unnecessary, so it is better to go through the list and remove unnecessary words.
Determination of frequency
To do this, create a new project (specify the name and region), in the second tab select “Frequency collection”, check the first three options:


Once the frequency collection is completed, you can download the file. Let's see what happened. We have already written about how to predict traffic by keywords; if you haven’t read it yet, be sure to read it.
I will only say that I do not recommend using dummy queries for promotion, i.e. words for which the frequency with the “!Key” operators is equal to zero.
Keyword Clustering
Clustering is the division of keywords into groups from a logical point of view and based on search engine results. After distributing requests into groups, you will essentially receive a ready-made site structure.
To do this, click on “Clustering” and create a new project:

We name the project “Special equipment3” (any name of your choice), select a search engine (we chose Yandex), and also indicate the region:

The next step is setting up the collection. First you need to select the type of clustering algorithm. These algorithms work on the same principle (comparing search engine TOPs), but are designed to solve different problems:
- Wordstat – suitable for creating a website structure.
- Manual markers - suitable if you already have a ready-made site structure and you need keywords by which to promote existing site pages.
- Combined (manual markers + Wordstat) – suitable for the task of simultaneously selecting keywords for the existing site structure and expanding it.
Here we indicate the minimum frequency that we use and the clustering accuracy:

The greater the clustering accuracy, the greater the number of keys that will fall into one group. For blogs and portals, accuracy is not so important (you can put 3 or 4). But for sites with competitive topics, it is better to choose a higher grouping accuracy.
As you can see from the screenshot, we have selected all acceptable grouping accuracies. This does not affect the cost of clustering, but we will be able to determine which group is more suitable for us.
Let's proceed to the next stage - downloading a file with keywords:

The result of clustering in xlsx format looks like this:

Based on this file, you can create a Relevance Map and form technical specifications for copywriters.
Slovoeb program
One of the best free programs for compiling a semantic core. Many people call it “Key Collector’s little brother.”
Pros:
- The program is absolutely free.
- Availability of tips, description of the program and its tools.
- Clear interface.
Minuses:
- Requires installation on a computer.
- There is no automatic query clustering.
- No program updates.
Setting up the program
You can order the development of SYS and maps (look in the “Optimization and technical support” section).
The headache of any professional SEO is to collect good semantics. I just received a new project for promotion, and in this post I will show you the actual collection of a large semantic core for the site.
Although I will do this example on the basis of an online store, the principle itself can be fully applied to any type of site - corporate, service site, information project.
How to collect a semantic core for an online store
It all starts with an analysis of the client project, competitors’ websites and drawing up a primary structure. The goal of this task is to understand in which areas the semantics need to be collected.
I draw the primary structure in Xmind, I got this diagram.
Now the fun begins.
How to collect a semantic core using the key collector

After the kernel is cleaned, I make a new iteration - I throw the keys back into parsing in wordstat, adwords and hints, then I clean it again and the finished kernel is obtained.
For this project, I did not do an iteration, since the project is quite large and there are enough requests to provide the predicted results.
Collecting the semantic core of competitors
The next step is to collect the semantics of competitors using the website keys.so. In my opinion, this is just an awesome service for parsing other people's requests, it has little garbage and a very large database.
I just find several competitors’ sites (3-4 are enough) for the most important queries, put them into the service, and it returns ALL the keys by which they are promoted.



Then I also drive them into the key collector, clean them of various garbage in the same way as described above, and I get an excellent semantic core of competitors, plus the already assembled core.
Collecting semantics in Bukvariks
Another program that I use at work is bukvarix.com. Excellent program, little garbage, very large database. The only negative is that it weighs like hell. Only in compressed form is about 40 GB, and in unpacked form more than 170.
I also put all the words from the structure into it.

I clean the parsing result in the same way through the key collector. As a result, I get another semantic core.
Now the final point - you need to put it all together (initial parsing of the key collector, competitors from key.so and bukvariks), clear away duplicates and here it is - ready-made semantics for the online store.
After collection, but that's a completely different story.
In terms of time, on average, at my leisurely pace, I assemble such a core in about 2 weeks. Whether it’s long or fast, I don’t know, this is my pace.
I repeat that this scheme is suitable for any type of site, and for my information projects I collect semantics in exactly the same way.
Of course, you can quickly manually assemble a basic semantic core for a site for free and online using the same service yandex.wordstat.ru, but it will turn out to be one-sided, very small, and you simply will have few opportunities to expand it.
The semantic core is a scary name that SEOs came up with to denote a rather simple thing. We just need to select the key queries for which we will promote our site.
And in this article I will show you how to correctly compose a semantic core so that your site quickly reaches the TOP, and does not stagnate for months. There are also “secrets” here.
And before we move on to compiling the SY, let's figure out what it is and what we should ultimately come to.
What is the semantic core in simple words
Oddly enough, but the semantic core is a regular Excel file, which contains a list of key queries for which you (or your copywriter) will write articles for the site.
For example, this is what my semantic core looks like:
I have marked in green those key queries for which I have already written articles. Yellow - those for which I plan to write articles in the near future. And colorless cells mean that these requests will come a little later.
For each key query, I have determined the frequency, competitiveness, and come up with a “catchy” title. You should get approximately the same file. Now my CN consists of 150 keywords. This means that I am provided with “material” for at least 5 months in advance (even if I write one article a day).
Below we will talk about what you should prepare for if you suddenly decide to order the collection of the semantic core from specialists. Here I will say briefly - they will give you the same list, but only for thousands of “keys”. However, in SY it is not quantity that is important, but quality. And we will focus on this.
Why do we need a semantic core at all?
But really, why do we need this torment? You can, after all, just write quality articles and attract an audience, right? Yes, you can write, but you won’t be able to attract people.
The main mistake of 90% of bloggers is simply writing high-quality articles. I'm not kidding, they have really interesting and useful materials. But search engines don’t know about it. They are not psychics, but just robots. Accordingly, they do not rank your article in the TOP.
There is another subtle point with the title. For example, you have a very high-quality article on the topic “How to properly conduct business in a face book.” There you describe everything about Facebook in great detail and professionally. Including how to promote communities there. Your article is the highest quality, useful and interesting on the Internet on this topic. No one was lying next to you. But it still won't help you.
Why high-quality articles fall out of the TOP
Imagine that your site was visited not by a robot, but by a live inspector (assessor) from Yandex. He realized that you have the coolest article. And hands put you in first place in the search results for the request “Promoting a community on Facebook.”
Do you know what will happen next? You will fly out of there very soon anyway. Because no one will click on your article, even in first place. People enter the query “Promoting a community on Facebook,” and your headline is “How to properly run a business in a face book.” Original, fresh, funny, but... not on request. People want to see exactly what they were looking for, not your creativity.
Accordingly, your article will empty its place in the TOP search results. And a living assessor, an ardent admirer of your work, can beg the authorities as much as he likes to leave you at least in the TOP 10. But it won't help. All the first places will be taken by empty articles, like the husks of sunflower seeds, that yesterday’s schoolchildren copied from each other.
But these articles will have the correct “relevant” title - “Promoting a community on Facebook from scratch” ( step by step, in 5 steps, from A to Z, free etc.) Is it offensive? Still would. Well, fight against injustice. Let's create a competent semantic core so that your articles take the well-deserved first places.
Another reason to start writing SYNOPSIS right now
There is one more thing that for some reason people don’t think much about. You need to write articles often - at least every week, and preferably 2-3 times a week, in order to gain more traffic and quickly.
Everyone knows this, but almost no one does it. And all because they have “creative stagnation”, “they just can’t force themselves”, “they’re just lazy”. But in fact, the whole problem lies in the absence of a specific semantic core.
I entered one of my basic keys, “smm,” into the search field, and Yandex immediately gave me a dozen hints about what else might be of interest to people who are interested in “smm.” All I have to do is copy these keys into a notebook. Then I will check each of them in the same way, and collect hints on them as well.
After the first stage of collecting key words, you should end up with a text document containing 10-30 broad basic keys, which we will work with further.
Step #2 — Parsing basic keys in SlovoEB
Of course, if you write an article for the request “webinar” or “smm”, then a miracle will not happen. You will never be able to reach the TOP for such a broad request. We need to break the basic key into many small queries on this topic. And we will do this using a special program.
I use KeyCollector, but it's paid. You can use a free analogue - the SlovoEB program. You can download it from the official website.
The most difficult thing about working with this program is setting it up correctly. I show you how to properly set up and use Sloboeb. But in that article I focus on selecting keys for Yandex Direct.
And here let’s look step by step at the features of using this program for creating a semantic core for SEO.
First, we create a new project and name it by the broad key that you want to parse.
I usually give the project the same name as my base key to avoid confusion later. And yes, I will warn you against one more mistake. Don't try to parse all base keys at once. Then it will be very difficult for you to filter out “empty” key queries from golden grains. Let's parse one key at a time.
After creating the project, we carry out the basic operation. That is, we actually parse the key through Yandex Wordstat. To do this, click on the “Worstat” button in the program interface, enter your base key, and click “Start collection”.
For example, let's parse the base key for my blog “contextual advertising”.
After this, the process will start, and after some time the program will give us the result - up to 2000 key queries that contain “contextual advertising”.
Also, next to each request there will be a “dirty” frequency - how many times this key (+ its word forms and tails) was searched per month through Yandex. But I do not advise drawing any conclusions from these figures.
Step #3 - Collecting the exact frequency for the keys
Dirty frequency will not show us anything. If you focus on it, then don’t be surprised when your key for 1000 requests does not bring a single click per month.
We need to identify pure frequency. And to do this, we first select all the found keys with checkmarks, and then click on the “Yandex Direct” button and start the process again. Now Slovoeb will look for the exact request frequency per month for each key.
Now we have an objective picture - how many times what query was entered by Internet users over the past month. I now propose to group all key queries by frequency to make it easier to work with them.
To do this, click on the “filter” icon in the “Frequency” column. ", and specify - filter out keys with the value "less than or equal to 10".
Now the program will show you only those requests whose frequency is less than or equal to the value “10”. You can delete these queries or copy them to another group of key queries for future use. Less than 10 is very little. Writing articles for these requests is a waste of time.
Now we need to select those key queries that will bring us more or less good traffic. And for this we need to find out one more parameter - the level of competitiveness of the request.
Step #4 — Checking the competitiveness of requests
All “keys” in this world are divided into 3 types: high-frequency (HF), mid-frequency (MF), low-frequency (LF). They can also be highly competitive (HC), moderately competitive (SC) and low competitive (LC).
As a rule, HF requests are also VC. That is, if a query is often searched on the Internet, then there are a lot of sites that want to promote it. But this is not always the case; there are happy exceptions.
The art of compiling a semantic core lies precisely in finding queries that have a high frequency and a low level of competition. It is very difficult to manually determine the level of competition.
You can focus on indicators such as the number of main pages in the TOP 10, length and quality of texts. level of trust and tits of sites in the TOP search results upon request. All of this will give you some idea of how tough the competition is for rankings for this particular query.
But I recommend you use Mutagen service. It takes into account all the parameters that I mentioned above, plus a dozen more that neither you nor I have probably even heard of. After analysis, the service gives an exact value - what level of competition this request has.
Here I checked the query “setting up contextual advertising in google adwords”. Mutagen showed us that this key has a competitiveness of "more than 25" - this is the maximum value it shows. And this query has only 11 views per month. So it definitely doesn’t suit us.
We can copy all the keys that we found in Slovoeb and do a mass check in Mutagen. After that, all we have to do is look through the list and take those requests that have a lot of requests and a low level of competition.
Mutagen is a paid service. But you can do 10 checks per day for free. In addition, the cost of testing is very low. In all the time I have been working with him, I have not yet spent even 300 rubles.
By the way, about the level of competition. If you have a young site, then it is better to choose queries with a competition level of 3-5. And if you have been promoting for more than a year, then you can take 10-15.
By the way, regarding the frequency of requests. We now need to take the final step, which will allow you to attract a lot of traffic even for low-frequency queries.
Step #5 — Collecting “tails” for the selected keys
As has been proven and tested many times, your site will receive the bulk of traffic not from the main keywords, but from the so-called “tails”. This is when a person enters strange key queries into the search bar, with a frequency of 1-2 per month, but there are a lot of such queries.
To see the “tail”, just go to Yandex and enter the key query of your choice into the search bar. Here's roughly what you'll see.
Now you just need to write down these additional words in a separate document and use them in your article. Moreover, there is no need to always place them next to the main key. Otherwise, search engines will see “over-optimization” and your articles will fall in search results.
Just use them in different places in your article, and then you will receive additional traffic from them as well. I would also recommend that you try to use as many word forms and synonyms as possible for your main key query.
For example, we have a request - “Setting up contextual advertising”. Here's how to reformulate it:
- Setup = set up, make, create, run, launch, enable, place...
- Contextual advertising = context, direct, teaser, YAN, adwords, kms. direct, adwords...
You never know exactly how people will search for information. Add all these additional words to your semantic core and use them when writing texts.
So, we collect a list of 100 - 150 key queries. If you are creating a semantic core for the first time, it may take you several weeks.
Or maybe break his eyes? Maybe there is an opportunity to delegate the compilation of FL to specialists who will do it better and faster? Yes, there are such specialists, but you don’t always need to use their services.
Is it worth ordering SY from specialists?
By and large, specialists in compiling a semantic core will only give you steps 1 - 3 from our scheme. Sometimes, for a large additional fee, they will do steps 4-5 - (collecting tails and checking the competitiveness of requests).
After that, they will give you several thousand key queries that you will need to work with further.
And the question here is whether you are going to write the articles yourself, or hire copywriters for this. If you want to focus on quality rather than quantity, then you need to write it yourself. But then it won't be enough for you to just get a list of keys. You will need to choose topics that you understand well enough to write a quality article.
And here the question arises - why then do we actually need specialists in FL? Agree, parsing the base key and collecting exact frequencies (steps #1-3) is not at all difficult. This will literally take you half an hour.
The most difficult thing is to choose HF requests that have low competition. And now, as it turns out, you need HF-NCs, on which you can write a good article. This is exactly what will take you 99% of your time working on the semantic core. And no specialist will do this for you. Well, is it worth spending money on ordering such services?
When are the services of FL specialists useful?
It’s another matter if you initially plan to attract copywriters. Then you don't have to understand the subject of the request. Your copywriters won’t understand it either. They will simply take several articles on this topic and compile “their” text from them.
Such articles will be empty, miserable, almost useless. But there will be many of them. On your own, you can write a maximum of 2-3 quality articles per week. And an army of copywriters will provide you with 2-3 shitty texts a day. At the same time, they will be optimized for requests, which means they will attract some traffic.
In this case, yes, calmly hire FL specialists. Let them also draw up a technical specification for copywriters at the same time. But you understand, this will also cost some money.
Summary
Let's go over the main ideas in the article again to reinforce the information.
- The semantic core is simply a list of key queries for which you will write articles on the site for promotion.
- It is necessary to optimize texts for precise key queries, otherwise even your highest-quality articles will never reach the TOP.
- SY is like a content plan for social networks. It helps you avoid falling into a “creative crisis” and always know exactly what you will write about tomorrow, the day after tomorrow and in a month.
- To compile a semantic core, it is convenient to use the free program Slovoeb, you only need it.
- Here are the five steps of compiling the NL: 1 - Selection of basic keys; 2 - Parsing basic keys; 3 - Collection of exact frequency for queries; 4 — Checking the competitiveness of keys; 5 – Collection of “tails”.
- If you want to write articles yourself, then it is better to create a semantic core yourself, for yourself. Specialists in the preparation of synonyms will not be able to help you here.
- If you want to work on quantity and use copywriters to write articles, then it is quite possible to delegate and compile the semantic core. If only there was enough money for everything.
I hope this instruction was useful to you. Save it to your favorites so as not to lose it, and share it with your friends. Don't forget to download my book. There I show you the fastest way from zero to the first million on the Internet (a summary from personal experience over 10 years =)
See you later!
Yours Dmitry Novoselov
