Efficient use of the GPU. Parallel computing on NVIDIA GPU or supercomputer in every home Using gpu
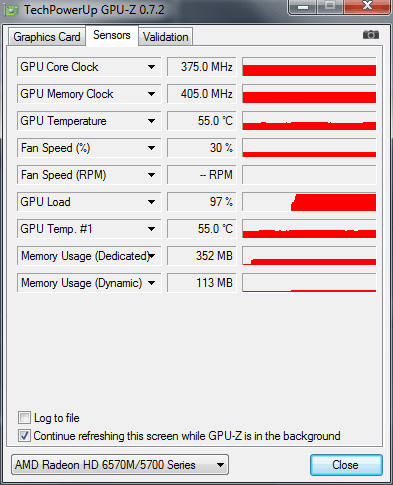
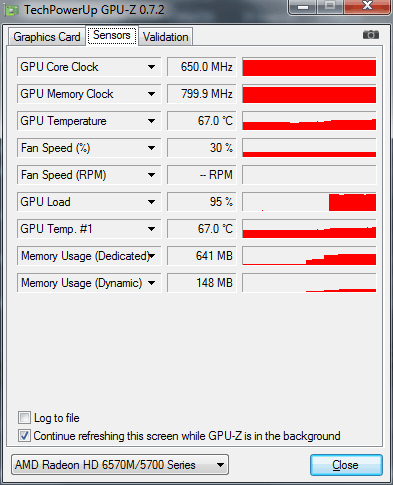
The question often began to appear: why is there no GPU acceleration in Adobe Media Encoder CC? And the fact that Adobe Media Encoder uses GPU acceleration, we found out, and also noted the nuances of its use. There is also a statement: that support for GPU acceleration has been removed from the Adobe Media Encoder CC program. This is an erroneous opinion and follows from the fact that the main program Adobe Premiere Pro CC can now work without a registered and recommended video card, and to enable the GPU engine in Adobe Media Encoder CC, the video card must be registered in the documents: cuda_supported_cards or opencl_supported_cards. If everything is clear with nVidia chipsets, just take the name of the chipset and enter it in the cuda_supported_cards document. That when using AMD graphics cards it is necessary to prescribe not the name of the chipset, but the code name of the kernel. So, let's check in practice how to enable the GPU engine in Adobe Media Encoder CC on an ASUS N71JQ laptop with ATI Mobility Radeon HD 5730 discrete graphics. Technical data of ATI Mobility Radeon HD 5730 graphics adapter shown by GPU-Z utility:
We launch Adobe Premiere Pro CC and turn on the engine: Mercury Playback Engine GPU Acceleration (OpenCL).

Three DSLR videos on the timeline, one above the other, two of them creating a picture-in-picture effect.

Ctrl+M, select the Mpeg2-DVD preset, remove the black bars on the sides using the Scale To Fill option. We also enable increased quality for tests without a GPU: MRQ (Use Maximum Render Quality). Click on the button: Export. CPU load up to 20% and random access memory 2.56 GB.

The GPU load of the ATI Mobility Radeon HD 5730 chipset is 97% and 352MB of onboard video memory. The laptop was tested while running on battery, so the graphics core / memory operate at lower frequencies: 375 / 810 MHz.
Final rendering time: 1 minute and 55 seconds(on/off MRQ when using the GPU engine, does not affect the final rendering time).
With the Use Maximum Render Quality checkbox checked, now click on the button: Queue.


Processor clock speeds when running on battery: 930 MHz.


Run AMEEncodingLog and see the final rendering time: 5 minutes and 14 seconds.

We repeat the test, but with the Use Maximum Render Quality checkbox unchecked, click on the button: Queue.

Final rendering time: 1 minute and 17 seconds.

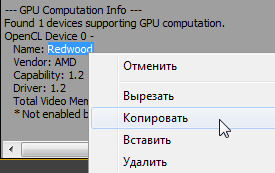
Now turn on the GPU engine in Adobe Media Encoder CC, launch Adobe Premiere Pro CC, press the key combination: Ctrl + F12, execute Console > Console View and type GPUSniffer in the Command field, press Enter.

Select and copy the name in GPU Computation Info.
In directory Adobe software Premiere Pro CC open the document opencl_supported_cards, and in alphabetical order we drive in the code name of the chipset, Ctrl + S.

Click on the button: Queue, and we get GPU acceleration for rendering an Adobe Premiere Pro CC project in Adobe Media Encoder CC.
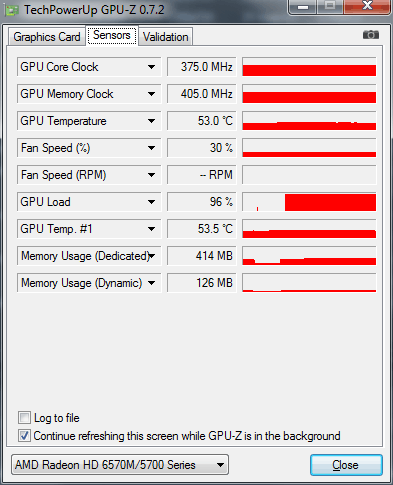
Final time: 1 minute and 55 seconds.

We connect the laptop to the outlet, and repeat the results of the miscalculations. Queue, the MRQ checkbox is unchecked, without turning on the engine, the RAM load has grown a little:

Processor clock speeds: 1.6GHz when running from the outlet and turning on the mode: High performance.

Final time: 46 seconds.

We turn on the engine: Mercury Playback Engine GPU Acceleration (OpenCL), as you can see from the network, the laptop video card operates at its base frequencies, the GPU load in Adobe Media Encoder CC reaches 95%.
Total rendering time decreased from 1 minute 55 seconds, before 1 minute and 5 seconds.

*Adobe Media Encoder CC now uses the graphics processing unit (GPU) for rendering. CUDA and OpenCL standards are supported. In Adobe Media Encoder CC, the GPU engine is used for the following rendering processes:
- Changing the definition (from high to standard and vice versa).
- Timecode filter.
- Pixel format conversions.
- Interleaving.
When a Premiere Pro project is rendered, AME uses the GPU rendering settings specified for that project. This will take full advantage of the GPU rendering capabilities of Premiere Pro. AME projects are rendered using a limited set of GPU rendering capabilities. If the sequence is rendered using native support, the GPU setting from AME is applied and the project setting is ignored. In this case, all of Premiere Pro's GPU rendering capabilities are used directly in AME. If the project contains 3rd party VSTs, the project's GPU setting is used. The sequence is encoded using PProHeadless, as in earlier versions of AME. If the Enable Native Premiere Pro Sequence Import checkbox is unchecked, PProHeadless and the GPU setting are always used.
We read about the hidden section on system drive laptop ASUS N71JQ.
There are never too many cores...
Modern GPUs are monstrous fast beasts capable of chewing gigabytes of data. However, a person is cunning and, no matter how computing power grows, he comes up with tasks more and more difficult, so there comes a moment when you have to state with sadness that optimization is needed 🙁
This article describes the basic concepts, in order to make it easier to navigate in the theory of gpu-optimization and the basic rules, so that these concepts have to be accessed less often.
The reasons why GPUs are effective for dealing with large amounts of data that require processing:
- they have great opportunities for parallel execution of tasks (many, many processors)
- high memory bandwidth
Memory bandwidth- this is how much information - bits or gigabytes - can be transferred per unit of time, a second or a processor cycle.
One of the tasks of optimization is to use the maximum throughput - to increase performance throughput(ideally, it should be equal to memory bandwidth).
To improve bandwidth usage:
- increase the amount of information - use the bandwidth to the full (for example, each stream works with float4)
- reduce latency - the delay between operations
Latency- the time interval between the moments when the controller requested a specific memory cell and the moment when the data became available to the processor for executing instructions. We cannot influence the delay itself in any way - these restrictions are present at the hardware level. It is due to this delay that the processor can simultaneously serve several threads - while thread A has requested to allocate memory to it, thread B can calculate something, and thread C can wait until the requested data arrives.
How to reduce latency if synchronization is used:
- reduce the number of threads in a block
- increase the number of block groups
Using GPU resources to the full - GPU Occupancy
In highbrow conversations about optimization, the term often flashes - gpu occupancy or kernel occupancy- it reflects the efficiency of the use of resources-capacities of the video card. Separately, I note that even if you use all the resources, this does not mean that you are using them correctly.
The computing power of the GPU is hundreds of processors greedy for calculations, when creating a program - the kernel (kernel) - the burden of distributing the load on them falls on the shoulders of the programmer. A mistake can result in most of these precious resources being idle for no reason. Now I will explain why. You have to start from afar.
Let me remind you that the warp ( warp in NVidia terminology, wavefront - in AMD terminology) - a set of threads that simultaneously perform the same kernel function on the processor. Threads united by the programmer into blocks are divided into warps by the thread scheduler (separately for each multiprocessor) - while one warp is running, the second is waiting for memory requests to be processed, etc. If some of the warp threads are still performing calculations, while others have already done their best, then there is an inefficient use of the computing resource - popularly referred to as idle power.
Every synchronization point, every branch of logic can create such an idle situation. The maximum divergence (branching of the execution logic) depends on the size of the warp. For NVidia GPUs, this is 32, for AMD, 64.
To reduce multiprocessor downtime during warp execution:
- minimize waiting time barriers
- minimize the divergence of execution logic in the kernel function
To effectively solve this problem, it makes sense to understand how warps are formed (for the case with several dimensions). In fact, the order is simple - first in X, then in Y, and last in Z.
the core is launched with 64×16 blocks, the threads are divided into warps in the order X, Y, Z - i.e. the first 64 elements are split into two warps, then the second, and so on.

The kernel starts with 16x64 blocks. The first and second 16 elements are added to the first warp, the third and fourth elements are added to the second warp, and so on.
How to reduce divergence (remember - branching is not always the cause of a critical performance loss)
- when adjacent threads have different execution paths - many conditions and transitions on them - look for ways to re-structure
- look for an unbalanced load of threads and decisively remove it (this is when we not only have conditions, but because of these conditions, the first thread always calculates something, and the fifth one does not fall into this condition and is idle)
How to get the most out of GPU resources
GPU resources, unfortunately, also have their limitations. And, strictly speaking, before launching the kernel function, it makes sense to define limits and take these limits into account when distributing the load. Why is it important?
Video cards have limits on the total number of threads that one multiprocessor can execute, the maximum number of threads in one block, the maximum number of warps on one processor, restrictions on different types of memory, etc. All this information can be requested both programmatically, through the corresponding API, and previously using utilities from the SDK. (deviceQuery modules for NVidia devices, CLInfo modules for AMD video cards).
General practice:
- the number of thread blocks/workgroups must be a multiple of the number of stream processors
- block/workgroup size must be a multiple of the warp size
At the same time, it should be borne in mind that the absolute minimum - 3-4 warps / wayfronts are spinning simultaneously on each processor, wise guides advise to proceed from the consideration - at least seven wayfronts. At the same time - do not forget the restrictions on the iron!
Keeping all these details in your head quickly gets boring, therefore, for calculating gpu-occupancy, NVidia offered an unexpected tool - an excel (!) Calculator full of macros. There you can enter information on the maximum number of threads for SM, the number of registers and the size of the shared (shared) memory available on the stream processor, and the used parameters for launching functions - and it gives a percentage of resource use efficiency (and you tear your hair out realizing what to use all the cores you are missing registers).
usage information:
http://docs.nvidia.com/cuda/cuda-c-best-practices-guide/#calculating-occupancy
GPU and memory operations
Video cards are optimized for 128-bit memory operations. Those. ideally, each memory manipulation, ideally, should change 4 four-byte values at a time. The main annoyance for the programmer is that modern compilers for the GPU are not able to optimize such things. This has to be done right in the function code and, on average, brings fractions of a percentage of performance gains. The frequency of memory requests has a much greater impact on performance.
The problem is as follows - each request returns in response a piece of data that is a multiple of 128 bits. And each thread uses only a quarter of it (in the case of a normal four-byte variable). When adjacent threads simultaneously work with data located sequentially in memory cells, this reduces the total number of memory accesses. This phenomenon is called combined read and write operations ( coalesced access - good! both read and write) - and with the correct organization of the code ( strided access to contiguous chunk of memory - bad!) can significantly improve performance. When organizing your kernel - remember - contiguous access - within the elements of one row of memory, working with the elements of a column is no longer so efficient. Want more details? I liked this pdf - or google for " memory coalescing techniques “.
The leading position in the “bottleneck” nomination is occupied by another memory operation - copy data from host memory to GPU . Copying does not happen anyhow, but from a memory area specially allocated by the driver and the system: when a request is made to copy data, the system first copies this data there, and only then uploads it to the GPU. Data transfer rate is limited by bus bandwidth PCI Express xN (where N is the number of data lines) through which modern video cards communicate with the host.
However, extra copying of slow memory on the host is sometimes an unjustified overhead. The way out is to use the so-called pinned memory - a specially marked memory area, so that the operating system is not able to perform any operations with it (for example, unload to swap / move at its discretion, etc.). Data transfer from the host to the video card is carried out without the participation of the operating system - asynchronously, through DMA (direct memory access).
And finally, a little more about memory. Shared memory on a multiprocessor is usually organized in the form of memory banks containing 32-bit words - data. The number of banks traditionally varies from one GPU generation to another - 16/32 If each thread requests data from a separate bank, everything is fine. Otherwise, several read / write requests to one bank are obtained and we get - a conflict ( shared memory bank conflict). Such conflicting calls are serialized and therefore executed sequentially, not in parallel. If all threads access the same bank, a “broadcast” response is used ( broadcast) and there is no conflict. There are several ways to effectively deal with access conflicts, I liked it description of the main techniques for getting rid of conflicts of access to memory banks – .
How to make mathematical operations even faster? Remember that:
- double precision calculations are heavy operation load with fp64 >> fp32
- constants of the form 3.13 in the code, by default, are interpreted as fp64 if you do not explicitly specify 3.14f
- to optimize mathematics, it will not be superfluous to consult in the guides - and are there any flags for the compiler
- vendors include features in their SDKs that take advantage of device features to achieve performance (often at the expense of portability)
It makes sense for CUDA developers to pay close attention to the concept cuda stream, allowing you to run several core functions at once on one device or combine asynchronous copying of data from the host to the device during the execution of functions. OpenCL does not yet provide such functionality 🙁
Profiling junk:
NVifia Visual Profiler is an interesting utility that analyzes both CUDA and OpenCL kernels.
P.S. As a longer optimization guide, I can recommend googling all sorts of best practice guide for OpenCL and CUDA.
- ,
GPU Computing
CUDA (Compute Unified Device Architecture) technology is a software and hardware architecture that allows computing using NVIDIA GPUs that support GPGPU (arbitrary computing on video cards) technology. The CUDA architecture first appeared on the market with the release of the eighth generation NVIDIA chip - G80 and is present in all subsequent series of graphics chips that are used in the GeForce, ION, Quadro and Tesla accelerator families.
The CUDA SDK allows programmers to implement, in a special simplified dialect of the C programming language, algorithms that can be run on NVIDIA GPUs and include special functions in the C program text. CUDA gives the developer the opportunity, at his own discretion, to organize access to the instruction set of the graphics accelerator and manage its memory, organize complex parallel computing on it.
Story
In 2003, Intel and AMD were in a joint race for the most powerful processor. For several years as a result of this race clock frequencies grew significantly, especially after the release of Intel Pentium 4.
After the increase in clock frequencies (between 2001 and 2003, the Pentium 4 clock frequency doubled from 1.5 to 3 GHz), and users had to be content with tenths of a gigahertz, which manufacturers brought to the market (from 2003 to 2005, clock frequencies increased 3 to 3.8 GHz).
Architectures optimized for high clock speeds, such as Prescott, also began to experience difficulties, and not only in production. Chip manufacturers have faced challenges in overcoming the laws of physics. Some analysts even predicted that Moore's law would cease to operate. But that did not happen. The original meaning of the law is often misrepresented, but it refers to the number of transistors on the surface of a silicon core. For a long time, an increase in the number of transistors in the CPU was accompanied by a corresponding increase in performance - which led to a distortion of the meaning. But then the situation became more complicated. The designers of the CPU architecture approached the law of gain reduction: the number of transistors that needed to be added for the desired increase in performance became more and more, leading to a dead end.
The reason why GPU manufacturers have not faced this problem is very simple: CPUs are designed to get the best performance on a stream of instructions that process different data (both integers and floating point numbers), perform random access to memory, etc. d. Until now, developers have been trying to provide greater instruction parallelism - that is, to execute as many instructions as possible in parallel. So, for example, superscalar execution appeared with the Pentium, when under certain conditions it was possible to execute two instructions per clock. The Pentium Pro received out-of-order execution of instructions, which made it possible to optimize the performance of computing units. The problem is that the parallel execution of a sequential stream of instructions has obvious limitations, so blindly increasing the number of computing units does not give a gain, since most of the time they will still be idle.
GPU operation is relatively simple. It consists of taking a group of polygons on one side and generating a group of pixels on the other. Polygons and pixels are independent of each other, so they can be processed in parallel. Thus, in the GPU, it is possible to allocate a large part of the crystal for computing units, which, unlike the CPU, will actually be used.

The GPU differs from the CPU not only in this. Memory access in the GPU is very coupled - if a texel is read, then after a few cycles, the adjacent texel will be read; when a pixel is written, the neighboring one will be written after a few cycles. By intelligently organizing memory, you can get performance close to the theoretical bandwidth. This means that the GPU, unlike the CPU, does not require a huge cache, since its role is to speed up texturing operations. All it takes is a few kilobytes containing a few texels used in bilinear and trilinear filters.
First calculations on the GPU
The very first attempts at such an application were limited to the use of some hardware features, such as rasterization and Z-buffering. But in the current century, with the advent of shaders, they began to speed up the calculation of matrices. In 2003, a separate section was allocated to SIGGRAPH for GPU computing, and it was called GPGPU (General-Purpose computation on GPU).
The best known BrookGPU is the Brook stream programming language compiler, designed to perform non-graphical computations on the GPU. Before its appearance, developers using the capabilities of video chips for calculations chose one of two common APIs: Direct3D or OpenGL. This seriously limited the use of the GPU, because 3D graphics use shaders and textures that parallel programmers are not required to know about, they use threads and cores. Brook was able to help make their task easier. These streaming extensions to the C language, developed at Stanford University, hid the 3D API from programmers and presented the video chip as a parallel coprocessor. The compiler parsed a .br file with C++ code and extensions, producing code linked to a DirectX, OpenGL, or x86-enabled library.
The appearance of Brook aroused the interest of NVIDIA and ATI and further opened up a whole new sector of it - parallel computers based on video chips.
Further, some researchers from the Brook project moved to the NVIDIA development team to introduce a hardware-software parallel computing strategy, opening up a new market share. And the main advantage of this NVIDIA initiative was that the developers perfectly know all the capabilities of their GPUs to the smallest detail, and there is no need to use the graphics API, and you can work with the hardware directly using the driver. The result of this team's efforts is NVIDIA CUDA.
Areas of application of parallel computations on the GPU
When computing is transferred to the GPU, in many tasks acceleration is achieved by 5-30 times compared to fast general-purpose processors. The biggest numbers (of the order of 100x speedup and even more!) are achieved on code that is not very well suited for calculations using SSE blocks, but is quite convenient for the GPU.
These are just some examples of speedups of synthetic code on the GPU versus SSE vectorized code on the CPU (according to NVIDIA):
Fluorescence microscopy: 12x.
Molecular dynamics (non-bonded force calc): 8-16x;
Electrostatics (direct and multi-level Coulomb summation): 40-120x and 7x.
The table that NVIDIA shows on all presentations, which shows the speed of GPUs relative to CPUs.

List of major applications in which GPU computing is used: image and signal analysis and processing, physics simulation, computational mathematics, computational biology, financial calculations, databases, gas and liquid dynamics, cryptography, adaptive radiation therapy, astronomy, sound processing, bioinformatics , biological simulations, computer vision, data analysis ( data mining), digital cinema and television, electromagnetic simulations, geographic information systems, military applications, mining planning, molecular dynamics, magnetic resonance imaging (MRI), neural networks, oceanographic research, particle physics, protein folding simulation, quantum chemistry, ray tracing, visualization , radars, hydrodynamic modeling (reservoir simulation), artificial intelligence, satellite data analysis, seismic exploration, surgery, ultrasound, video conferencing.
Benefits and Limitations of CUDA
From a programmer's point of view, the graphics pipeline is a set of processing stages. The geometry block generates triangles, and the rasterization block generates pixels displayed on the monitor. The traditional GPGPU programming model is as follows:

To transfer computations to the GPU within the framework of such a model, a special approach is needed. Even element-by-element addition of two vectors will require drawing the shape to the screen or to an off-screen buffer. The figure is rasterized, the color of each pixel is calculated according to a given program (pixel shader). The program reads the input data from the textures for each pixel, adds them up, and writes them to the output buffer. And all these numerous operations are needed for what is written in a single operator in a conventional programming language!
Therefore, the use of GPGPU for general purpose computing has a limitation in the form of too much complexity for developers to learn. And there are enough other restrictions, because a pixel shader is just a formula for the dependence of the final color of a pixel on its coordinates, and the pixel shader language is a language for writing these formulas with a C-like syntax. The early GPGPU methods are a clever trick to harness the power of the GPU, but without any convenience. The data there is represented by images (textures), and the algorithm is represented by a rasterization process. It should be noted and a very specific model of memory and execution.
NVIDIA's hardware and software architecture for computing on GPUs from NVIDIA differs from previous GPGPU models in that it allows writing programs for GPUs in real C with standard syntax, pointers, and the need for a minimum of extensions to access the computing resources of video chips. CUDA does not depend on graphics APIs, and has some features designed specifically for general purpose computing.
Advantages of CUDA over the traditional approach to GPGPU computing
CUDA provides access to 16 KB of shared memory per multiprocessor, which can be used to organize a cache with a higher bandwidth than texture fetches;
More efficient data transfer between system and video memory;
No need for graphics APIs with redundancy and overhead;
Linear memory addressing, and gather and scatter, the ability to write to arbitrary addresses;
Hardware support for integer and bit operations.
Main limitations of CUDA:
Lack of recursion support for executable functions;
The minimum block width is 32 threads;
Closed CUDA architecture owned by NVIDIA.
The weaknesses of programming with previous GPGPU methods are that these methods do not use vertex shader execution units in previous non-unified architectures, data is stored in textures and output to an off-screen buffer, and multi-pass algorithms use pixel shader units. GPGPU limitations include: insufficiently efficient use of hardware capabilities, memory bandwidth limitations, no scatter operation (only gather), mandatory use of the graphics API.
The main advantages of CUDA over previous GPGPU methods stem from the fact that this architecture is designed to efficiently use non-graphics computing on the GPU and uses the C programming language without requiring algorithms to be ported to a form convenient for the concept of the graphics pipeline. CUDA offers a new GPU computing path that does not use graphics APIs, offering random memory access (scatter or gather). Such an architecture is free from the disadvantages of GPGPU and uses all the execution units, and also expands the capabilities through integer mathematics and bit shift operations.
CUDA opens up some hardware features not available from the graphics APIs, such as shared memory. This is a small amount of memory (16 kilobytes per multiprocessor) that blocks of threads have access to. It allows you to cache the most frequently accessed data and can provide faster performance than using texture fetches for this task. This, in turn, reduces the throughput sensitivity of parallel algorithms in many applications. For example, it is useful for linear algebra, fast Fourier transform, and image processing filters.
More convenient in CUDA and memory access. The code in the graphics API outputs data as 32 single-precision floating-point values (RGBA values simultaneously to eight render targets) in predefined areas, and CUDA supports scatter recording - an unlimited number of records at any address. Such advantages make it possible to execute some algorithms on the GPU that cannot be efficiently implemented using GPGPU methods based on the graphics API.
Also, graphical APIs necessarily store data in textures, which requires prior packing of large arrays into textures, which complicates the algorithm and forces the use of special addressing. And CUDA allows you to read data at any address. Another advantage of CUDA is the optimized communication between CPU and GPU. And for developers who want to access the low level (for example, when writing another programming language), CUDA offers the possibility of low-level assembly language programming.
Disadvantages of CUDA
One of the few disadvantages of CUDA is its poor portability. This architecture works only on the video chips of this company, and not on all of them, but starting from the GeForce 8 and 9 series and the corresponding Quadro, ION and Tesla. NVIDIA gives a figure of 90 million CUDA-compatible video chips.
Alternatives to CUDA
Framework for writing computer programs associated with parallel computing on various graphic and central processors. The OpenCL framework includes a programming language based on the C99 standard and an application programming interface (API). OpenCL provides instruction-level and data-level parallelism and is an implementation of the GPGPU technique. OpenCL is a completely open standard and there are no license fees to use it.
The goal of OpenCL is to complement OpenGL and OpenAL, which are open industry standards for 3D computer graphics and sound, by taking advantage of the power of the GPU. OpenCL is developed and maintained by the Khronos Group, a non-profit consortium that includes many major companies including Apple, AMD, Intel, nVidia, Sun Microsystems, Sony Computer Entertainment, and others.
CAL/IL(Compute Abstraction Layer/Intermediate Language)
ATI Stream Technology is a set of hardware and software technologies, which allow the use of graphic AMD processors, together with central processing unit, to speed up many applications (not just graphics).
Applications for ATI Stream are computationally demanding applications such as financial analysis or seismic data processing. The use of a stream processor made it possible to increase the speed of some financial calculations by 55 times compared to solving the same problem using only the central processor.
NVIDIA does not consider ATI Stream technology to be a very strong competitor. CUDA and Stream are two different technologies that are at different levels of development. Programming for ATI products is much more difficult - their language is more like an assembler. CUDA C, on the other hand, is a much higher level language. Writing on it is more convenient and easier. For large development companies, this is very important. If we talk about performance, we can see that its peak value in ATI products is higher than in NVIDIA solutions. But again, it all comes down to how to get this power.
DirectX11 (DirectCompute)
An application programming interface that is part of DirectX, a set of APIs from Microsoft that is designed to run on IBM PC-compatible computers running operating systems families Microsoft Windows. DirectCompute is designed to perform general purpose computations on GPUs, being an implementation of the GPGPU concept. DirectCompute was originally published as part of DirectX 11, but was later made available for DirectX 10 and DirectX 10.1 as well.
NVDIA CUDA in the Russian scientific community.
As of December 2009, the CUDA programming model is being taught at 269 universities around the world. In Russia, training courses on CUDA are taught at Moscow, St. Petersburg, Kazan, Novosibirsk and Perm State Universities, the International University of the Nature of Society and Man "Dubna", the Joint Institute for Nuclear Research, the Moscow Institute of Electronic Technology, Ivanovo State Power Engineering University, BSTU. V. G. Shukhova, MSTU im. Bauman, RKhTU im. Mendeleev, the Russian Research Center "Kurchatov Institute", the Interregional Supercomputer Center of the Russian Academy of Sciences, the Taganrog Institute of Technology (TTI SFedU).
GPU Computing with C++ AMP
So far, in the discussion of parallel programming techniques, we have considered only processor cores. We have gained some skills in parallelizing programs across multiple processors, synchronizing access to shared resources, and using high-speed synchronization primitives without the use of locks.
However, there is another way to parallelize programs - graphics processing units (GPUs), which have more cores than even high-end processors. GPU cores are great for implementing parallel data processing algorithms, and their large number more than compensates for the inconvenience of running programs on them. In this article, we will get acquainted with one of the ways to execute programs on the GPU, using a set of C ++ language extensions called C++AMP.
The C++ AMP extensions are based on the C++ language, which is why this article will show examples in C++. However, with moderate use of the mechanism of interactions in. NET, you will be able to use C++ AMP algorithms in your .NET programs. But we will talk about this at the end of the article.
Introduction to C++ AMP
In essence, a GPU is a processor like any other, but with a special set of instructions, a large number of cores, and its own memory access protocol. However, there are big differences between modern graphics processors and conventional processors, and understanding them is the key to creating programs that use computing power efficiently. GPU.
Modern GPUs have a very small instruction set. This implies some limitations: the inability to call functions, a limited set of supported data types, the absence of library functions, and others. Some operations, such as conditional jumps, can cost significantly more than similar operations performed on conventional processors. Obviously, porting large amounts of code from the CPU to the GPU under these conditions requires a lot of effort.
The number of cores in the average GPU is significantly higher than in the average conventional processor. However, some tasks are too small or do not allow themselves to be broken down into a large enough number of pieces to benefit from the use of the GPU.
Synchronization support between GPU cores performing the same task is very scarce, and completely absent between GPU cores performing different tasks. This circumstance requires synchronization of the GPU with a conventional processor.
The question immediately arises, what tasks are suitable for solving on a GPU? Keep in mind that not every algorithm is suitable for running on a GPU. For example, GPUs don't have access to I/O devices, so you can't improve the performance of a program that retrieves RSS feeds from the Internet by using the GPU. However, many computational algorithms can be transferred to the GPU and their massive parallelization can be ensured. Below are a few examples of such algorithms (this list is by no means exhaustive):
image sharpening and sharpening, and other transformations;
fast Fourier transform;
transposition and matrix multiplication;
sorting numbers;
hash inversion "on the forehead".
A great source for more examples is the Microsoft Native Concurrency Blog, which provides code snippets and explanations for various algorithms implemented in C++ AMP.
C++ AMP is a framework included with visual studio 2012, which gives C++ developers an easy way to perform computations on the GPU and requires only a DirectX 11 driver. Microsoft has released C++ AMP as an open specification that any compiler vendor can implement.
The C++ AMP framework allows you to execute code on graphics accelerators, which are computing devices. Using the DirectX 11 driver, the C++ AMP framework dynamically detects all accelerators. C++ AMP also includes a software accelerator emulator and a conventional processor-based emulator, WARP, which serves as a fallback on systems without a GPU or with a GPU but lacks a DirectX 11 driver and uses multiple cores and SIMD instructions.
And now let's start exploring an algorithm that can be easily parallelized to run on a GPU. The implementation below takes two vectors of the same length and computes a pointwise result. It's hard to imagine anything more straightforward:
Void VectorAddExpPointwise(float* first, float* second, float* result, int length) ( for (int i = 0; i< length; ++i) { result[i] = first[i] + exp(second[i]); } }
To parallelize this algorithm on a conventional processor, it is required to split the range of iterations into several subranges and start one thread of execution for each of them. We've spent quite a bit of time in previous articles on exactly this way of parallelizing our first prime number search example - we've seen how to do it by manually creating threads, passing jobs to a thread pool, and using Parallel.For and PLINQ to automatically parallelize. Recall also that when parallelizing similar algorithms on a conventional processor, we took special care not to split the task into too small tasks.
For the GPU, these warnings are not needed. GPUs have many cores that execute threads very quickly, and the cost of a context switch is much lower than conventional CPUs. Following is the snippet trying to use the function parallel_for_each from the C++ AMP framework:
#include
Now let's examine each part of the code separately. Note right away that the general form of the main loop has been retained, but the for loop originally used has been replaced by a call to the parallel_for_each function. In fact, the principle of converting a loop into a function or method call is not new to us - this technique has already been demonstrated using the Parallel.For() and Parallel.ForEach() methods from the TPL library.
Next, the input data (parameters first, second and result) are wrapped with instances array_view. The array_view class is used to wrap the data passed to the GPU (accelerator). Its template parameter defines the data type and its dimension. In order to execute instructions on the GPU that access data originally processed on a regular CPU, someone or something must take care of copying the data to the GPU, because most modern graphics cards are separate devices with their own memory. Array_view instances solve this problem - they ensure that data is copied on demand and only when they are really needed.
When the GPU completes the job, the data is copied back. By instantiating array_view with a const type argument, we ensure that first and second are copied into GPU memory, but not copied back. Likewise, calling discard_data(), we exclude copying result from the memory of a conventional processor to the memory of the accelerator, but this data will be copied in the opposite direction.
The parallel_for_each function takes an extent object that specifies the form of the data to be processed and the function to apply to each element in the extent object. In the example above, we used a lambda function, support for which was introduced in the ISO C++2011 (C++11) standard. The restrict (amp) keyword instructs the compiler to check that the function body can be executed on the GPU and disables most of the C++ syntax that cannot be compiled into GPU instructions.
lambda function parameter, index<1>object represents a one-dimensional index. It must match the extent object being used - if we were to declare the extent object to be two-dimensional (for example, defining the shape of the source data as a two-dimensional matrix), the index would also need to be two-dimensional. An example of such a situation is given below.
Finally, the method call synchronize() at the end of the VectorAddExpPointwise method, it ensures that the results of calculations from array_view avResult performed by the GPU are copied back to the result array.
This concludes our first introduction to the world of C++ AMP, and we are now ready for more detailed explorations, as well as more interesting examples that demonstrate the benefits of using parallel computing on the GPU. Vector addition is not the best algorithm and not the best candidate for demonstrating GPU usage due to the large data copy overhead. The next subsection will show two more interesting examples.
Matrix multiplication
The first "real" example we'll look at is matrix multiplication. For implementation, we will take a simple cubic algorithm for matrix multiplication, and not the Strassen algorithm, which has a runtime close to cubic ~O(n 2.807). Given two matrices, an m x w matrix A and a w x n matrix B, the following program will multiply them and return the result, an m x n matrix C:
Void MatrixMultiply(int* A, int m, int w, int* B, int n, int* C) ( for (int i = 0; i< m; ++i) { for (int j = 0; j < n; ++j) { int sum = 0; for (int k = 0; k < w; ++k) { sum += A * B; } C = sum; } } }
There are several ways to parallelize this implementation, and if you want to parallelize this code to run on a normal processor, the right choice would be to parallelize the outer loop. However, the GPU has a sufficiently large number of cores, and by parallelizing only the outer loop, we will not be able to create a sufficient number of tasks to load all the cores with work. So it makes sense to parallelize the two outer loops while leaving the inner loop untouched:
Void MatrixMultiply (int* A, int m, int w, int* B, int n, int* C) ( array_view
This implementation still closely resembles the sequential implementation of the matrix multiplication and vector addition example above, except for the index, which is now two-dimensional and available in the inner loop using the . How much faster is this version than the sequential alternative running on a conventional processor? Multiplying two 1024 x 1024 matrices (integers) the serial version on a regular CPU takes an average of 7350 milliseconds, while the GPU version - hold on tight - is 50 milliseconds, 147 times faster!
Simulation of particle motion
The examples of solving problems on the GPU presented above have a very simple implementation of the inner loop. It is clear that this will not always be the case. The Native Concurrency blog linked above demonstrates an example of modeling gravitational interactions between particles. The simulation includes an infinite number of steps; at each step, new values of the elements of the acceleration vector for each particle are calculated and then their new coordinates are determined. Here, the vector of particles is subjected to parallelization - with a sufficiently large number of particles (from several thousand and more), you can create a sufficiently large number of tasks to load all the cores of the GPU.
The basis of the algorithm is the implementation of determining the result of interactions between two particles, as shown below, which can be easily transferred to the GPU:
// here float4 are vectors with four elements, // representing the particles involved in the operations void bodybody_interaction (float4& acceleration, const float4 p1, const float4 p2) restrict(amp) ( float4 dist = p2 - p1; // w is not here uses float absDist = dist.x*dist.x + dist.y*dist.y + dist.z*dist.z; float invDist = 1.0f / sqrt(absDist); float invDistCube = invDist*invDist*invDist; acceleration + = dist*PARTICLE_MASS*invDistCube; )
The initial data at each modeling step is an array with the coordinates and velocities of the particles, and as a result of the calculations, a new array is created with the coordinates and velocities of the particles:
Struct particle ( float4 position, velocity; // implementations of constructor, copy constructor, and // operator = with restrict(amp) omitted to save space ); void simulation_step(array
With the help of an appropriate graphical interface, modeling can be very interesting. The full example provided by the C++ AMP development team can be found on the Native Concurrency Blog. On my system with an Intel Core i7 processor and a Geforce GT 740M graphics card, 10,000 particle motion simulation runs at ~2.5 frames per second (steps per second) using the serial version running on a regular processor and 160 frames per second using the optimized the version running on the GPU is a huge performance boost.
Before wrapping up this section, there is one more important feature of the C++ AMP framework that can further improve the performance of code running on the GPU. GPUs support programmable data cache(often called shared memory). The values stored in this cache are shared by all threads of execution in the same tile. Thanks to memory tiling, programs based on the C++ AMP framework can read data from the graphics card's memory into the shared memory of the tile and then access it from multiple threads of execution without re-retrieving the data from the graphics card's memory. Accessing shared tile memory is approximately 10 times faster than accessing graphics card memory. In other words, you have reasons to keep reading.
To provide a tiled version of the parallel loop, the parallel_for_each method is passed tiled_extent domain, which divides the multidimensional extent object into multidimensional tiles, and the tiled_index lambda parameter, which specifies the global and local ID of the thread within the tile. For example, a 16x16 matrix can be divided into 2x2 tiles (as shown in the figure below) and then passed to the parallel_for_each function:
Extent<2>matrix(16,16); tiled_extent<2,2>tiledMatrix = matrix.tile<2,2>(); parallel_for_each (tiledMatrix, [=](tiled_index<2,2>idx) restrict(amp) ( // ... ));

Each of the four threads of execution that belong to the same tile can share the data stored in the block.
When performing operations with matrices, in the GPU core, instead of the standard index<2>, as in the examples above, you can use idx.global. Proper use of local tiling and local indexes can provide significant performance gains. To declare tiled memory shared by all threads of execution in a single tile, local variables can be declared with the tile_static specifier.
In practice, the method of declaring shared memory and initializing its individual blocks in different threads of execution is often used:
Parallel_for_each(tiledMatrix, [=](tiled_index<2,2>idx) restrict(amp) ( // 32 bytes shared by all threads in tile_static block int local; // assign value to element for this thread of execution local = 42; ));
Obviously, any benefit from using shared memory can only be obtained if access to this memory is synchronized; that is, threads should not access memory until it has been initialized by one of them. Synchronization of threads in a mosaic is done using objects tile_barrier(reminiscent of the Barrier class from the TPL library) - they can continue execution only after calling the tile_barrier.Wait () method, which will return control only when all threads call tile_barrier.Wait. For example:
Parallel_for_each (tiledMatrix, (tiled_index<2,2>idx) restrict(amp) ( // 32 bytes shared by all threads in a tile_static block int local; // assign a value to an element for this thread of execution local = 42; // idx.barrier - instance of tile_barrier idx.barrier.wait(); // Now this thread can access the "local" array // using indexes of other threads of execution! ));
Now is the time to translate the acquired knowledge into a concrete example. Let's return to the implementation of matrix multiplication, performed without the use of tiled memory organization, and add the described optimization to it. Let's say that the size of the matrix is a multiple of 256 - this will allow us to work with blocks of 16 x 16. The nature of matrices allows the possibility of block-by-block multiplication, and we can take advantage of this feature (in fact, dividing matrices into blocks is a typical optimization of the matrix multiplication algorithm, providing a more efficient cpu cache usage).
The essence of this approach is as follows. To find C i,j (element in row i and column j in the result matrix), we need to calculate the dot product between A i,* (i-th row of the first matrix) and B *,j (j-th column in the second matrix ). However, this is equivalent to calculating the partial dot products of the row and column and then summing the results. We can use this circumstance to transform the matrix multiplication algorithm into a tiled version:
Void MatrixMultiply(int* A, int m, int w, int* B, int n, int* C) ( array_view The essence of the described optimization is that each thread in the mosaic (256 threads are created for a 16 x 16 block) initializes its element in 16 x 16 local copies of fragments of the original matrices A and B. Each thread in the mosaic requires only one row and one column of these blocks, but all threads together will access each row and each column 16 times. This approach significantly reduces the number of accesses to the main memory. To calculate the element (i,j) in the result matrix, the algorithm needs the complete i-th row of the first matrix and the j-th column of the second matrix. When the flows are tiled 16x16 represented in the diagram and k=0, the shaded areas in the first and second matrices will be read into shared memory. The thread of execution that computes element (i,j) in the result matrix will compute the partial dot product of the first k elements from the i-th row and the j-th column of the original matrices. In this example, tiling provides a huge performance boost. The tiled version of matrix multiplication is much faster than the simple version, taking about 17 milliseconds (for the same original 1024 x 1024 matrices), which is 430 times faster than the normal CPU version! Before we end our discussion of the C++ AMP framework, we'd like to mention the tools (in Visual Studio) available to developers. Visual Studio 2012 offers a debugger for the graphics processing unit (GPU) that allows you to set breakpoints, examine the call stack, read and change the values of local variables (some accelerators support GPU debugging directly; for others, Visual Studio uses a software simulator), and a profiler that allows you to evaluate the benefits that an application receives from parallelization of operations using a GPU. For more information about the debugging features in Visual Studio, see the Walkthrough. Debugging a C++ AMP Application" on MSDN. So far, this article has only shown examples in C++, but there are several ways to harness the power of the GPU in managed applications. One way is to use interoperability tools that allow you to offload GPU core work to low-level C++ components. This solution is great for those who want to use the C++ AMP framework or have the ability to use out-of-the-box C++ AMP components in managed applications. Another way is to use a library that works directly with the GPU from managed code. Several such libraries currently exist. For example, GPU.NET and CUDAfy.NET (both are commercial offerings). The following is an example from the GPU.NET GitHub repository demonstrating the implementation of the dot product of two vectors: Public static void MultiplyAddGpu(double a, double b, double c) ( int ThreadId = BlockDimension.X * BlockIndex.X + ThreadIndex.X; int TotalThreads = BlockDimension.X * GridDimension.X; for (int ElementIdx = ThreadId; ElementIdx I'm of the opinion that it's much easier and more efficient to learn a language extension (powered by C++ AMP) than trying to orchestrate library-level interactions or make significant changes to the IL language. So, after we looked at the possibilities of parallel programming in .NET and using the GPU, no one doubts that the organization of parallel computing is an important way to improve performance. In many servers and workstations around the world, the invaluable computing power of conventional and GPU processors remains unused, because applications simply do not use them. The Task Parallel Library gives us a unique opportunity to include all available CPU cores, although this will have to solve some of the most interesting problems of synchronization, excessive fragmentation of tasks, and unequal distribution of work between threads of execution. The C++ AMP framework and other multi-purpose GPU parallel libraries can be successfully used to parallelize computations across hundreds of GPU cores. Finally, there is a previously unexplored opportunity to gain performance from the use of distributed computing cloud technologies, which have recently become one of the main directions in the development of information technology. AMD/ATI Radeon Architecture Features This is similar to the birth of new biological species, when living beings evolve to improve their adaptability to the environment during the development of habitats. Similarly, GPUs, starting with accelerated rasterization and texturing of triangles, have developed additional abilities to execute shader programs for coloring these same triangles. And these abilities turned out to be in demand in non-graphical computing, where in some cases they provide a significant performance gain compared to traditional solutions. We draw analogies further - after a long evolution on land, mammals penetrated into the sea, where they pushed out ordinary marine inhabitants. In the competitive struggle, mammals used both new advanced abilities that appeared on the earth's surface and those specially acquired for adaptation to life in the water. In the same way, GPUs, based on the advantages of the architecture for 3D graphics, are increasingly acquiring special functionality useful for non-graphics tasks. So, what allows the GPU to claim its own sector in the field of general-purpose programs? The microarchitecture of the GPU is built very differently from conventional CPUs, and it has certain advantages from the very beginning. Graphics tasks involve independent parallel processing of data, and the GPU is natively multi-threaded. But this parallelism is only a joy to him. The microarchitecture is designed to exploit the large number of threads that need to be executed. The GPU consists of several dozen (30 for Nvidia GT200, 20 for Evergreen, 16 for Fermi) processor cores, which are called Streaming Multiprocessor in Nvidia terminology, and SIMD Engine in ATI terminology. Within the framework of this article, we will call them miniprocessors, because they execute several hundred program threads and can do almost everything that a regular CPU can, but still not everything. Marketing names are confusing - they, for greater importance, indicate the number of functional modules that can subtract and multiply: for example, 320 vector "cores" (cores). These kernels are more like grains. It's better to think of the GPU as a multi-core processor with many cores executing many threads at the same time. Each miniprocessor has local memory, 16 KB for the GT200, 32 KB for the Evergreen, and 64 KB for the Fermi (essentially a programmable L1 cache). It has a similar access time to the L1 cache of a conventional CPU and performs similar functions of delivering data to function modules as quickly as possible. In the Fermi architecture, a portion of the local memory can be configured as a regular cache. In the GPU, local memory is used to quickly exchange data between executing threads. One of the usual schemes for a GPU program is as follows: first, data from the global memory of the GPU is loaded into local memory. This is just ordinary video memory, located (like system memory) separately from “its own” processor - in the case of video, it is soldered by several microcircuits on the textolite of the video card. Next, several hundred threads work with this data in local memory and write the result to global memory, after which it is transferred to the CPU. It is the responsibility of the programmer to write instructions for loading and unloading data from local memory. In essence, this is the partitioning of data [of a specific task] for parallel processing. The GPU also supports atomic write/read instructions to memory, but they are inefficient and are usually required at the final stage for "gluing" the results of calculations of all miniprocessors. Local memory is common for all threads running in the miniprocessor, so, for example, in Nvidia terminology it is even called shared, and the term local memory means exactly the opposite, namely: a certain personal area of a separate thread in global memory, visible and accessible only to it. But in addition to local memory, the miniprocessor has another memory area, in all architectures, about four times larger in volume. It is divided equally among all executing threads; these are registers for storing variables and intermediate results of calculations. Each thread has several dozen registers. The exact number depends on how many threads the miniprocessor is running. This number is very important, since the latency of the global memory is very high, hundreds of cycles, and in the absence of caches, there is nowhere to store intermediate results of calculations. And one more important feature of the GPU: “soft” vectorization. Each miniprocessor has a large number of compute modules (8 for the GT200, 16 for the Radeon, and 32 for the Fermi), but they can only execute the same instruction, with the same program address. The operands in this case can be different, different threads have their own. For example, the instruction add the contents of two registers: it is simultaneously executed by all computing devices, but different registers are taken. It is assumed that all threads of the GPU program, performing parallel processing of data, generally move in a parallel course through the program code. Thus, all computing modules are loaded evenly. And if the threads, due to branches in the program, have diverged in their path of code execution, then the so-called serialization occurs. Then not all computing modules are used, since the threads submit different instructions for execution, and the block of computing modules can execute, as we have already said, only an instruction with one address. And, of course, performance at the same time falls in relation to the maximum. The advantage is that vectorization is completely automatic, it is not programming using SSE, MMX, and so on. And the GPU itself handles the discrepancies. Theoretically, it is possible to write programs for the GPU without thinking about the vector nature of the executing modules, but the speed of such a program will not be very high. The downside is the large width of the vector. It is more than the nominal number of functional modules, and is 32 for Nvidia GPUs and 64 for Radeon. The threads are processed in blocks of the appropriate size. Nvidia calls this block of threads the term warp, AMD - wave front, which is the same thing. Thus, on 16 computing devices, a "wave front" 64 threads long is processed in four cycles (assuming the usual instruction length). The author prefers the term warp in this case, because of the association with the nautical term warp, denoting a rope tied from twisted ropes. So the threads "twist" and form an integral bundle. However, the “wave front” can also be associated with the sea: instructions arrive at the actuators in the same way as waves roll onto the shore one after another. If all the threads have progressed equally in the execution of the program (they are in the same place) and thus execute the same instruction, then everything is fine, but if not, it slows down. In this case, the threads from the same warp or wave front are in different places in the program, they are divided into groups of threads that have the same value of the instruction number (in other words, the instruction pointer). And as before, only the threads of one group are executed at one time - they all execute the same instruction, but with different operands. As a result, the warp is executed as many times slower, how many groups it is divided into, and the number of threads in the group does not matter. Even if the group consists of only one thread, it will still take as long to run as a full warp. In hardware, this is implemented by masking certain threads, that is, instructions are formally executed, but the results of their execution are not recorded anywhere and are not used in the future. Although each miniprocessor (Streaming MultiProcessor or SIMD Engine) executes instructions belonging to only one warp (a bunch of threads) at any given time, it has several dozen active warps in the executable pool. After executing the instructions of one warp, the miniprocessor executes not the next in turn instruction of the threads of this warp, but the instructions of someone else in the warp. That warp can be in a completely different place in the program, this will not affect the speed, since only inside the warp the instructions of all threads must be the same for execution at full speed. In this case, each of the 20 SIMD Engines has four active wave fronts, each with 64 threads. Each thread is indicated by a short line. Total: 64×4×20=5120 threads Thus, given that each warp or wave front consists of 32-64 threads, the miniprocessor has several hundred active threads that are executing almost simultaneously. Below we will see what architectural benefits such a large number of parallel threads promise, but first we will consider what limitations the miniprocessors that make up GPUs have. The main thing is that the GPU does not have a stack where function parameters and local variables could be stored. Due to the large number of threads for the stack, there is simply no room on the chip. Indeed, since the GPU simultaneously executes about 10,000 threads, with a single thread stack size of 100 KB, the total amount will be 1 GB, which is equal to the standard amount of all video memory. Moreover, there is no way to place a stack of any significant size in the GPU core itself. For example, if you put 1000 bytes of stack per thread, then only one miniprocessor will require 1 MB of memory, which is almost five times the total amount of local memory of the miniprocessor and the memory allocated for storing registers. Therefore, there is no recursion in the GPU program, and you can’t really turn around with function calls. All functions are directly substituted into the code when the program is compiled. This limits the scope of the GPU to computational tasks. It is sometimes possible to use a limited stack emulation using global memory for recursion algorithms with a known small iteration depth, but this is not a typical GPU application. To do this, it is necessary to specially develop an algorithm, to explore the possibility of its implementation without a guarantee of successful acceleration compared to the CPU. Fermi first introduced the ability to use virtual functions, but again, their use is limited by the lack of a large, fast cache for each thread. 1536 threads account for 48 KB or 16 KB L1, that is, virtual functions in the program can be used relatively rarely, otherwise the stack will also use slow global memory, which will slow down execution and, most likely, will not bring benefits compared to the CPU version. Thus, the GPU is presented as a computational coprocessor, into which data is loaded, they are processed by some algorithm, and a result is produced. But considers the GPU very fast. And in this he is helped by his high multithreading. A large number of active threads makes it possible to partly hide the large latency of the separately located global video memory, which is about 500 cycles. It is especially well leveled for code with a high density of arithmetic operations. Thus, a transistor-expensive L1-L2-L3 cache hierarchy is not required. Instead, many compute modules can be placed on a chip, providing outstanding arithmetic performance. In the meantime, the instructions of one thread or warp are being executed, the other hundreds of threads are quietly waiting for their data. Fermi introduced a second level cache of about 1 MB, but it cannot be compared with the caches of modern processors, it is more intended for communication between cores and various software tricks. If its size is divided among all tens of thousands of threads, each will have a very insignificant amount. But besides the latency of global memory, there are many more latencies in the computing device that need to be hidden. This is the latency of data transfer within the chip from computing devices to the first-level cache, that is, the local memory of the GPU, and to the registers, as well as the instruction cache. The register file, as well as the local memory, are located separately from the functional modules, and the speed of access to them is about a dozen cycles. And again, a large number of threads, active warps, can effectively hide this latency. Moreover, the total bandwidth (bandwidth) of access to the local memory of the entire GPU, taking into account the number of miniprocessors that make it up, is much greater than the bandwidth of access to the first-level cache in modern CPUs. The GPU can process significantly more data per unit of time. We can immediately say that if the GPU is not provided with a large number of parallel threads, then it will have almost zero performance, because it will work at the same pace, as if it was fully loaded, and do much less work. For example, let only one thread remain instead of 10,000: performance will drop by about a thousand times, because not only will not all blocks be loaded, but all latencies will also affect. The problem of hiding latencies is also acute for modern high-frequency CPUs; sophisticated methods are used to eliminate it - deep pipelining, out-of-order execution of instructions (out-of-order). This requires complex instruction execution schedulers, various buffers, etc., which takes up space on the chip. This is all required for best performance in single-threaded mode. But for the GPU, all this is not necessary, it is architecturally faster for computational tasks with a large number of threads. Instead, it converts multithreading into performance like a philosopher's stone turns lead into gold. The GPU was originally designed to optimally execute shader programs for triangle pixels, which are obviously independent and can be executed in parallel. And from this state, it evolved by adding various features (local memory and addressable access to video memory, as well as complicating the instruction set) into a very powerful computing device, which can still be effectively applied only for algorithms that allow highly parallel implementation using a limited amount of local memory. memory. One of the most classic GPU problems is the problem of calculating the interaction of N bodies that create a gravitational field. But if, for example, we need to calculate the evolution of the Earth-Moon-Sun system, then the GPU is a bad helper for us: there are few objects. For each object, it is necessary to calculate interactions with all other objects, and there are only two of them. In the case of the motion of the solar system with all the planets and their moons (about a couple of hundred objects), the GPU is still not very efficient. However, a multi-core processor, due to high overhead costs for thread management, will also not be able to show all its power, it will work in single-threaded mode. But if you also need to calculate the trajectories of comets and asteroid belt objects, then this is already a task for the GPU, since there are enough objects to create the required number of parallel calculation threads. The GPU will also perform well if it is necessary to calculate the collision of globular clusters of hundreds of thousands of stars. Another opportunity to use the power of the GPU in the N-body problem appears when you need to calculate many individual problems, albeit with a small number of bodies. For example, if you want to calculate the evolution of one system for different options for initial velocities. Then it will be possible to effectively use the GPU without problems. We have considered the basic principles of GPU organization, they are common for video accelerators of all manufacturers, since they initially had one target task - shader programs. However, manufacturers have found it possible to disagree on the details of the microarchitectural implementation. Although the CPUs of different vendors are sometimes very different, even if they are compatible, such as Pentium 4 and Athlon or Core. The architecture of Nvidia is already widely known, now we will look at Radeon and highlight the main differences in the approaches of these vendors. AMD graphics cards have received full support for general purpose computing since the Evergreen family, which also pioneered the DirectX 11 specification. The 47xx family cards have a number of significant limitations, which will be discussed below. Differences in local memory size (32 KB for Radeon versus 16 KB for GT200 and 64 KB for Fermi) are generally not fundamental. As well as the wave front size of 64 threads for AMD versus 32 threads per warp for Nvidia. Almost any GPU program can be easily reconfigured and tuned to these parameters. Performance can change by tens of percent, but in the case of a GPU, this is not so important, because a GPU program usually runs ten times slower than its counterpart for the CPU, or ten times faster, or does not work at all. More important is AMD's use of VLIW (Very Long Instruction Word) technology. Nvidia uses scalar simple instructions that operate on scalar registers. Its accelerators implement simple classical RISC. AMD graphics cards have the same number of registers as the GT200, but the registers are 128-bit vector. Each VLIW instruction operates on several four-component 32-bit registers, which is similar to SSE, but the capabilities of VLIW are much wider. This is not SIMD (Single Instruction Multiple Data) like SSE - here the instructions for each pair of operands can be different and even dependent! For example, let the components of register A be named a1, a2, a3, a4; for register B - similarly. Can be calculated with a single instruction that executes in one cycle, for example, the number a1×b1+a2×b2+a3×b3+a4×b4 or a two-dimensional vector (a1×b1+a2×b2, a3×b3+a4×b4 ). This was made possible thanks to the lower frequency of the GPU than the CPU, and a strong decrease in technical processes in recent years. This does not require any scheduler, almost everything is executed per clock. With vector instructions, Radeon's peak single-precision performance is very high, at teraflops. One vector register can store one double precision number instead of four single precision numbers. And one VLIW instruction can either add two pairs of doubles, or multiply two numbers, or multiply two numbers and add to the third. Thus, peak performance in double is about five times lower than in float. For older Radeon models, it corresponds to the performance of Nvidia Tesla on the new Fermi architecture and is much higher than the performance in double cards on the GT200 architecture. In consumer Geforce video cards based on Fermi, the maximum speed of double-calculations was reduced by four times. GPU manufacturers, unlike CPU manufacturers (first of all, x86-compatible ones), are not bound by compatibility issues. The GPU program is first compiled into some intermediate code, and when the program is run, the driver compiles this code into model-specific machine instructions. As described above, GPU manufacturers took advantage of this by inventing convenient ISA (Instruction Set Architecture) for their GPUs and changing them from generation to generation. In any case, this added some percentage of performance due to the lack (as unnecessary) of the decoder. But AMD went even further, inventing its own format for arranging instructions in machine code. They are not arranged sequentially (according to the program listing), but in sections. First comes the section of conditional jump instructions, which have links to sections of continuous arithmetic instructions corresponding to different branch branches. They are called VLIW bundles (bundles of VLIW instructions). These sections contain only arithmetic instructions with data from registers or local memory. Such an organization simplifies the flow of instructions and their delivery to the execution units. This is all the more useful given that VLIW instructions are relatively large. There are also sections for memory access instructions. GPUs from both manufacturers (both Nvidia and AMD) also have built-in instructions for quickly calculating basic mathematical functions, square root, exponent, logarithms, sines and cosines for single precision numbers in several cycles. There are special computing blocks for this. They "came" from the need to implement a fast approximation of these functions in geometry shaders. Even if someone did not know that GPUs are used for graphics, and only got acquainted with the technical characteristics, then by this sign he could guess that these computing coprocessors originated from video accelerators. Similarly, some traits of marine mammals have led scientists to believe that their ancestors were land creatures. But a more obvious feature that betrays the graphical origin of the device is the blocks for reading two-dimensional and three-dimensional textures with support for bilinear interpolation. They are widely used in GPU programs, as they provide faster and easier reading of read-only data arrays. One of the standard behaviors of a GPU application is to read arrays of initial data, process them in computational cores, and write the result to another array, which is then passed back to the CPU. Such a scheme is standard and common, because it is convenient for the GPU architecture. Tasks that require intensive reads and writes to one large area of global memory, thus containing data dependencies, are difficult to parallelize and efficiently implement on the GPU. Also, their performance will greatly depend on the latency of the global memory, which is very large. But if the task is described by the pattern "reading data - processing - writing the result", then you can almost certainly get a big boost from its execution on the GPU. For texture data in the GPU, there is a separate hierarchy of small caches of the first and second levels. It also provides acceleration from the use of textures. This hierarchy originally appeared in GPUs in order to take advantage of the locality of access to textures: obviously, after processing one pixel, a neighboring pixel (with a high probability) will require closely spaced texture data. But many algorithms for conventional computing have a similar nature of data access. So texture caches from graphics will be very useful. Although the size of the L1-L2 caches in Nvidia and AMD cards is approximately the same, which is obviously caused by the requirements for optimality in terms of game graphics, the latency of access to these caches differs significantly. Nvidia's access latency is higher, and texture caches in Geforce primarily help to reduce the load on the memory bus, rather than directly speed up data access. This is not noticeable in graphics programs, but is important for general purpose programs. In Radeon, the latency of the texture cache is lower, but the latency of the local memory of miniprocessors is higher. Here is an example: for optimal matrix multiplication on Nvidia cards, it is better to use local memory, loading the matrix there block by block, and for AMD, it is better to rely on a low-latency texture cache, reading matrix elements as needed. But this is already a rather subtle optimization, and for an algorithm that has already been fundamentally transferred to the GPU. This difference also shows up when using 3D textures. One of the first GPU computing benchmarks, which showed a serious advantage for AMD, just used 3D textures, as it worked with a three-dimensional data array. And texture access latency in Radeon is significantly faster, and the 3D case is additionally more optimized in hardware. To get maximum performance from the hardware of various companies, some tuning of the application for a specific card is needed, but it is an order of magnitude less significant than, in principle, the development of an algorithm for the GPU architecture. In this family, support for GPU computing is incomplete. Three important points can be noted. Firstly, there is no local memory, that is, it is physically there, but does not have the universal access required by the modern standard of GPU programs. It is programmatically emulated in global memory, meaning it won't benefit from using it as opposed to a full-featured GPU. The second point is limited support for various atomic memory operations instructions and synchronization instructions. And the third point is the rather small size of the instruction cache: starting from a certain program size, the speed slows down by several times. There are other minor restrictions as well. We can say that only programs that are ideally suited for the GPU will work well on this video card. Although a video card can show good results in Gigaflops in simple test programs that operate only with registers, it is problematic to effectively program something complex for it. If we compare AMD and Nvidia products, then, in terms of GPU computing, the 5xxx series looks like a very powerful GT200. So powerful that it surpasses Fermi in peak performance by about two and a half times. Especially after the parameters of the new Nvidia video cards were cut, the number of cores was reduced. But the appearance of the L2 cache in Fermi simplifies the implementation of some algorithms on the GPU, thus expanding the scope of the GPU. Interestingly, for well-optimized for the previous generation GT200 CUDA programs, Fermi's architectural innovations often did nothing. They accelerated in proportion to the increase in the number of computing modules, that is, less than twice (for single precision numbers), or even less, because the memory bandwidth did not increase (or for other reasons). And in tasks that fit well on the GPU architecture and have a pronounced vector nature (for example, matrix multiplication), Radeon shows performance relatively close to the theoretical peak and overtakes Fermi. Not to mention multi-core CPUs. Especially in problems with single precision numbers. But Radeon has a smaller die area, less heat dissipation, power consumption, higher yield and, accordingly, lower cost. And directly in the problems of 3D graphics, the Fermi gain, if any, is much less than the difference in the area of the crystal. This is largely due to the fact that Radeon's compute architecture, with 16 compute units per miniprocessor, a 64-thread wave front, and VLIW vector instructions, is perfect for its main task - computing graphics shaders. For the vast majority of ordinary users, gaming performance and price are priorities. From the point of view of professional, scientific programs, the Radeon architecture provides the best price-performance ratio, performance per watt and absolute performance in tasks that in principle fit well with the GPU architecture, allow for parallelization and vectorization. For example, in a fully parallel, easily vectorizable key selection problem, Radeon is several times faster than Geforce and several tens of times faster than CPU. This corresponds to the general AMD Fusion concept, according to which GPUs should complement the CPU, and in the future be integrated into the CPU core itself, just as the math coprocessor was previously transferred from a separate chip to the processor core (this happened about twenty years ago, before the appearance of the first Pentium processors). The GPU will be an integrated graphics core and a vector coprocessor for streaming tasks. Radeon uses a tricky technique of mixing instructions from different wave fronts when executed by function modules. This is easy to do since the instructions are completely independent. The principle is similar to the pipelined execution of independent instructions by modern CPUs. Apparently, this makes it possible to efficiently execute complex, multi-byte, vector VLIW instructions. On the CPU, this requires a sophisticated scheduler to identify independent instructions, or the use of Hyper-Threading technology, which also supplies the CPU with known independent instructions from different threads. 128 instructions of two wave fronts, each of which consists of 64 operations, are executed by 16 VLIW modules in eight cycles. There is an alternation, and each module actually has two cycles to execute an entire instruction, provided that it starts executing a new one in parallel on the second cycle. This probably helps to quickly execute a VLIW instruction like a1×a2+b1×b2+c1×c2+d1×d2, that is, execute eight such instructions in eight cycles. (Formally, it turns out, one per clock.) Nvidia apparently doesn't have this technology. And in the absence of VLIW, high performance using scalar instructions requires a high frequency of operation, which automatically increases heat dissipation and places high demands on the process (to force the circuit to run at a higher frequency). The disadvantage of Radeon in terms of GPU computing is a big dislike for branching. GPUs generally do not favor branching due to the above technology for executing instructions: immediately by a group of threads with one program address. (By the way, this technique is called SIMT: Single Instruction - Multiple Threads (one instruction - many threads), by analogy with SIMD, where one instruction performs one operation with different data.) . It is clear that if the program is not completely vector, then the larger the size of the warp or wave front, the worse, since when the path through the program of neighboring threads diverges, more groups are formed that must be executed sequentially (serialized). Let's say all the threads have dispersed, then in the case of a warp size of 32 threads, the program will run 32 times slower. And in the case of size 64, as in Radeon, it is 64 times slower. This is a noticeable, but not the only manifestation of "dislike". In Nvidia video cards, each functional module, otherwise called the CUDA core, has a special branch processing unit. And in Radeon video cards for 16 computing modules, there are only two branching control units (they are derived from the domain of arithmetic units). So even simple processing of a conditional branch instruction, even if its result is the same for all threads in the wave front, takes additional time. And the speed drops. AMD also manufactures CPUs. They believe that for programs with a lot of branches, the CPU is still better suited, and the GPU is intended for purely vector programs. So Radeon provides less efficient programming overall, but provides better price-performance in many cases. In other words, there are fewer programs that can be efficiently (beneficially) migrated from CPU to Radeon than programs that can be effectively run on Fermi. But on the other hand, those that can be effectively transferred will work more efficiently on Radeon in many ways. The technical specifications of Radeon themselves look attractive, although it is not necessary to idealize and absolutize GPU computing. But no less important for performance is the software necessary for developing and executing a GPU program - compilers from a high-level language and run-time, that is, a driver that interacts between a part of the program running on the CPU and the GPU itself. It is even more important than in the case of the CPU: the CPU does not need a driver to manage data transfer, and from the point of view of the compiler, the GPU is more finicky. For example, the compiler must make do with a minimum number of registers to store intermediate results of calculations, and carefully inline function calls, again using a minimum of registers. After all, the fewer registers a thread uses, the more threads you can run and the more fully load the GPU, better hiding the memory access time. And so the software support for Radeon products still lags behind the development of hardware. (In contrast to the situation with Nvidia, where the release of hardware was delayed, and the product was released in a stripped-down form.) More recently, AMD's OpenCL compiler was in beta status, with many flaws. It too often generated erroneous code, or refused to compile the code from the correct source code, or itself gave an error and crashed. Only at the end of spring came a release with high performance. It is also not without errors, but there are significantly fewer of them, and they, as a rule, appear on the sidelines when trying to program something on the verge of correctness. For example, they work with the uchar4 type, which specifies a 4-byte four-component variable. This type is in the OpenCL specifications, but it is not worth working with it on Radeon, because the registers are 128-bit: the same four components, but 32-bit. And such a uchar4 variable will still take up a whole register, only additional operations of packing and accessing individual byte components will still be required. A compiler shouldn't have any bugs, but there are no compilers without bugs. Even Intel Compiler after 11 versions has compilation errors. The identified bugs are fixed in the next release, which will be released closer to the fall. But there are still a lot of things that need to be improved. For example, until now, the standard GPU driver for Radeon does not support GPU computing using OpenCL. The user must download and install an additional special package. But the most important thing is the absence of any libraries of functions. For double-precision real numbers, there is not even a sine, cosine and exponent. Well, this is not required for matrix addition/multiplication, but if you want to program something more complex, you have to write all the functions from scratch. Or wait for a new SDK release. ACML (AMD Core Math Library) for the Evergreen GPU family with support for basic matrix functions should be released soon. At the moment, according to the author of the article, the use of the Direct Compute 5.0 API seems to be real for programming Radeon video cards, naturally taking into account the limitations: orientation to the Windows 7 and Windows Vista platforms. Microsoft has a lot of experience in making compilers, and we can expect a fully functional release very soon, Microsoft is directly interested in this. But Direct Compute is focused on the needs of interactive applications: to calculate something and immediately visualize the result - for example, the flow of a liquid over a surface. This does not mean that it cannot be used simply for calculations, but this is not its natural purpose. For example, Microsoft does not plan to add library functions to Direct Compute - exactly those that AMD does not have at the moment. That is, what can now be effectively calculated on Radeon - some not very sophisticated programs - can also be implemented on Direct Compute, which is much simpler than OpenCL and should be more stable. Plus, it's completely portable, and will run on both Nvidia and AMD, so you'll only have to compile the program once, while Nvidia's and AMD's OpenCL SDK implementations aren't exactly compatible. (In the sense that if you develop an OpenCL program on an AMD system using the AMD OpenCL SDK, it may not run as easily on Nvidia. You may need to compile the same text using the Nvidia SDK. And vice versa, of course.) Then, there is a lot of redundant functionality in OpenCL, since OpenCL is intended to be a universal programming language and API for a wide range of systems. And GPU, and CPU, and Cell. So in case you just want to write a program for a typical user system (processor plus video card), OpenCL does not seem to be, so to speak, "highly productive." Each function has ten parameters, and nine of them must be set to 0. And in order to set each parameter, you must call a special function that also has parameters. And the most important current advantage of Direct Compute is that the user does not need to install a special package: everything that is needed is already in DirectX 11. If we take the field of personal computers, then the situation is as follows: there are not many tasks that require a lot of computing power and are severely lacking in a conventional dual-core processor. It was as if big gluttonous, but clumsy monsters had crawled out of the sea onto land, and there was almost nothing to eat on land. And the primordial abodes of the earth's surface are decreasing in size, learning to consume less, as always happens when there is a shortage of natural resources. If today there was the same need for performance as 10-15 years ago, GPU computing would be accepted with a bang. And so the problems of compatibility and the relative complexity of GPU programming come to the fore. It is better to write a program that runs on all systems than a program that is fast but only runs on the GPU. The outlook for GPUs is somewhat better in terms of use in professional applications and the workstation sector, as there is more demand for performance. Plugins for GPU-enabled 3D editors are emerging: for example, for rendering with ray tracing - not to be confused with regular GPU rendering! Something is showing up for 2D and presentation editors as well, with faster creation of complex effects. Video processing programs are also gradually acquiring support for the GPU. The above tasks, in view of their parallel nature, fit well on the GPU architecture, but now a very large code base has been created, debugged, optimized for all CPU capabilities, so it will take time for good GPU implementations to appear. In this segment, such weaknesses of the GPU are also manifested, such as a limited amount of video memory - about 1 GB for conventional GPUs. One of the main factors that reduce the performance of GPU programs is the need to exchange data between the CPU and GPU over a slow bus, and due to the limited amount of memory, more data must be transferred. And here AMD's concept of combining GPU and CPU in one module looks promising: you can sacrifice the high bandwidth of graphics memory for easy and simple access to shared memory, moreover, with lower latency. This high bandwidth of the current DDR5 video memory is much more demanded directly by graphics programs than by most GPU computing programs. In general, the common memory of the GPU and CPU will simply significantly expand the scope of the GPU, make it possible to use its computing capabilities in small subtasks of programs. And most of all GPUs are in demand in the field of scientific computing. Several GPU-based supercomputers have already been built, which show very high results in the test of matrix operations. Scientific problems are so diverse and numerous that there is always a set that fits perfectly on the GPU architecture, for which the use of the GPU makes it easy to get high performance. If you choose one among all the tasks of modern computers, then it will be computer graphics - an image of the world in which we live. And the architecture optimal for this purpose cannot be bad. This is such an important and fundamental task that the hardware specially designed for it must be universal and be optimal for various tasks. Moreover, video cards are successfully evolving.
Alternatives to GPU Computing in .NET
Benefits of Architecture
Example
AMD Radeon microarchitecture details

Schematic diagram of the work of Radeon. Only one miniprocessor is shown out of 20 running in parallelConditional Branch Instruction Sections
Section 0 Branching 0 Link to section #3 of continuous arithmetic instructions
Section 1 Branching 1 Link to section #4
Section 2 Branching 2 Link to section #5
Sections of continuous arithmetic instructions
Section 3 VLIW instruction 0 VLIW instruction 1 VLIW instruction 2 VLIW instruction 3
Section 4 VLIW instruction 4 VLIW instruction 5
Section 5 VLIW instruction 6 VLIW instruction 7 VLIW instruction 8 VLIW instruction 9
Radeon 47xx Series Limitations
Advantages and disadvantages of Evergreen
measure 0 measure 1 measure 2 measure 3 bar 4 measure 5 bar 6 measure 7 VLIW module
wave front 0 wave front 1 wave front 0 wave front 1 wave front 0 wave front 1 wave front 0 wave front 1
→
instr. 0 instr. 0 instr. 16 instr. 16 instr. 32 instr. 32 instr. 48 instr. 48 VLIW0
→
instr. one …
…
…
…
…
…
…
VLIW1
→
instr. 2 …
…
…
…
…
…
…
VLIW2
→
instr. 3 …
…
…
…
…
…
…
VLIW3
→
instr. four …
…
…
…
…
…
…
VLIW4
→
instr. 5 …
…
…
…
…
…
…
VLIW5
→
instr. 6 …
…
…
…
…
…
…
VLIW6
→
instr. 7 …
…
…
…
…
…
…
VLIW7
→
instr. eight …
…
…
…
…
…
…
VLIW8
→
instr. 9 …
…
…
…
…
…
…
VLIW9
→
instr. ten …
…
…
…
…
…
…
VLIW10
→
instr. eleven …
…
…
…
…
…
…
VLIW11
→
instr. 12 …
…
…
…
…
…
…
VLIW12
→
instr. 13 …
…
…
…
…
…
…
VLIW13
→
instr. fourteen …
…
…
…
…
…
…
VLIW14
→
instr. fifteen …
…
…
…
…
…
…
VLIW15
API for GPU Computing
Problems of development of GPU computing
