Populate sql table. Moving from an ER diagram to a tabular model
SQL - Lesson 3. Creating tables and filling them with information
So, we got acquainted with data types, now we will improve the tables for our forum. Let's break them down first. And let's start with the users table. It has 4 columns:Id_user - integer values, so the type will be int, let's limit it to 10 characters - int (10).
name is a varchar string value, let's limit it to 20 characters - varchar(20).
email is a varchar string value, let's limit it to 50 characters - varchar(50).
password - varchar string value, let's limit it to 15 characters - varchar(15).
All field values are required, so you need to add the NOT NULL type.
id_user int(10) NOT NULL
name varchar(20) NOT NULL
email varchar(50) NOT NULL
The first column, as you remember from the conceptual model of our database, is the primary key (i.e. its values are unique and they uniquely identify a record). It is possible to follow the uniqueness on your own, but it is not rational. There is a special attribute in SQL for this - AUTO_INCREMENT, which, when accessing the table to add data, calculates the maximum value of this column, increases the resulting value by 1 and puts it in the column. Thus, a unique number is automatically generated in this column, and therefore the NOT NULL type is redundant. So, let's assign an attribute to a column with a primary key:
name varchar(20) NOT NULL
email varchar(50) NOT NULL
password varchar(15) NOT NULL
Now we need to specify that the id_user field is the primary key. To do this, SQL uses the keyword PRIMARY-KEY(), the name of the key field is indicated in parentheses. Let's make changes:
id_user int(10) AUTO_INCREMENT
name varchar(20) NOT NULL
email varchar(50) NOT NULL
password varchar(15) NOT NULL
PRIMARY KEY (id_user)
So, the table is ready, and its final version looks like this:
Create table users (
id_user int(10) AUTO_INCREMENT,
name varchar(20) NOT NULL,
email varchar(50) NOT NULL,
password varchar(15) NOT NULL,
PRIMARY KEY (id_user)
);
Now let's deal with the second table - topics (topics). Arguing similarly, we have the following fields:
id_author int(10) NOT NULL
PRIMARY KEY (id_topic)
But in our database model, the id_author field is a foreign key, i.e. it can only have values that are in the id_user field of the users table. In order to specify this in SQL there is a keyword FOREIGN-KEY(), which has the following syntax:
FOREIGN KEY (column_name_which_is_foreign_key) REFERENCES parent_table_name (parent_column_name);
Let's specify that id_author is a foreign key:
id_topic int(10) AUTO_INCREMENT
topic_name varchar(100) NOT NULL
id_author int(10) NOT NULL
PRIMARY KEY (id_topic)
FOREIGN KEY (id_author) REFERENCES users (id_user)
The table is ready, and its final version looks like this:
Create table topics (
id_topic int(10) AUTO_INCREMENT,
topic_name varchar(100) NOT NULL,
PRIMARY KEY(id_topic),
FOREIGN KEY (id_author) REFERENCES users (id_user)
);
The last table remains - posts (messages). Everything is similar here, only two foreign keys:
Create table posts (
id_post int(10) AUTO_INCREMENT,
message text NOT NULL,
id_author int(10) NOT NULL,
id_topic int(10) NOT NULL,
PRIMARY KEY (id_post),
FOREIGN KEY (id_author) REFERENCES users (id_user),
FOREIGN KEY (id_topic) REFERENCES topics (id_topic)
);
Please note that a table can have several foreign keys, and there can be only one primary key in MySQL. In the first lesson, we deleted our forum database, it's time to create it again.
Start the MySQL server (Start - Programs - MySQL - My SQL Server 5.1 - MySQL Command Line Client), enter a password, create a forum database (create database forum;), select it for use (use forum;) and create our three tables:
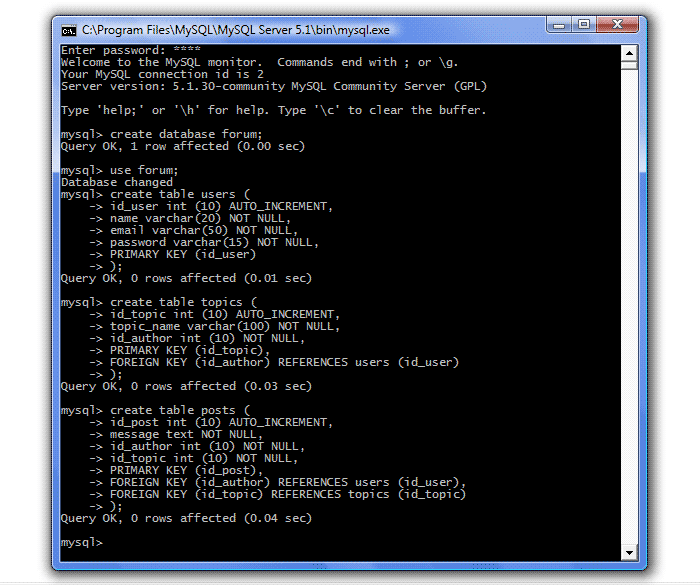
Please note that one command can be written in several lines using the Enter key (MySQL automatically substitutes a newline character ->), and only after the separator (semicolon) pressing the Enter key causes the query to be executed.
Remember, if you do something wrong, you can always drop a table or the entire database using the DROP statement. fix something in command line extremely inconvenient, so sometimes (especially at the initial stage) it's easier to write queries in some editor, such as Notepad, and then copy and paste them into a black window.
So, the tables are created to make sure of this, let's remember the team show tables:

And finally, let's look at the structure of our last posts table:

Now the meanings of all fields of the structure, except for the DEFAULT field, become clear. This is the default value field. We could specify a default value for some column (or for all). For example, if we had a field named "Married\Married" and of type ENUM ("yes", "no"), then it would make sense to make one of the values the default value. The syntax would be:
Married enum ("yes", "no") NOT NULL default("yes")
Those. this keyword is written with a space after the data type, and the default value is indicated in brackets.
But back to our tables. Now we need to enter data into our tables. On websites, you usually enter information into some html forms, then a script in some language (php, java ...) extracts this data from the form and enters it into the database. He does this by means of a SQL query to enter data into the database. We do not yet know how to write scripts in php, but now we will learn how to send SQL queries for entering data.
For this, the operator is used INSERT. Syntax can be used in two ways. The first option is used to enter data into all fields of the table:
INSERT INTO table_name VALUES ("first_column_value", "second_column_value", ..., "last_column_value");
Let's try to populate our users table with the following values:
INSERT INTO users VALUES ("1","sergey", " [email protected]", "1111");

The second option is used to enter data into some fields of the table:
INSERT INTO table_name ("column_name", "column_name") VALUES ("first_column_value", "second_column_value");
In our users table, all fields are required, but our first field has the keyword - AUTO_INCREMENT (i.e. it is filled in automatically), so we can skip this column:
INSERT INTO users (name, email, password) VALUES ("valera", " [email protected]", "2222");

If we had fields with the NULL type, i.e. optional, we could also ignore them. But if you try to leave the field with the value NOT NULL empty, the server will issue an error message and will not fulfill the request. In addition, when entering data, the server checks the relationships between the tables. Therefore, you cannot populate a field that is a foreign key with a value that is not in the related table. You will verify this by entering data in the remaining two tables.
But first, let's add information about a few more users. To add several lines at once, you just need to list the brackets with values separated by commas:

Now let's add data to the second table - topics. Everything is the same, but we must remember that the values in the id_author field must be present in the users table (users):

Now let's try to add another topic, but with an id_author that is not in the users table (because we only added 5 users to the users table, id=6 does not exist):

The server gives an error and says that it cannot enter such a line, because the foreign key field has a value that is not in the related users table.
Now let's add a few rows to the posts table (messages), remembering that we have 2 foreign keys in it, i.e. The id_author and id_topic that we will enter must be present in their associated tables:

So we have 3 tables that have data. The question arises - how to see what data is stored in the tables. This is what we will do in the next lesson.
Before you start creating a SQL table, you must define the database model. Design an ER diagram in which to define entities, attributes and relationships.
Basic concepts
Entities are objects or facts about which information needs to be stored. For example, an employee of a company or projects implemented by an enterprise. Attributes - a component that describes or qualifies an entity. For example, the attribute of the entity "employee" is the salary, and the attribute of the entity "project" is the estimated cost. Links are associations between two elements. It can be bidirectional. There is also a recursive relationship, that is, the relationship of an entity with itself.
It is also necessary to determine the keys and conditions under which the integrity of the database will be preserved. What does it mean? In other words, constraints that will help keep databases in a correct and consistent manner.
Moving from an ER diagram to a tabular model
Rules for the transition to a tabular model:
- Convert all entities to tables.
- Convert all attributes to columns, that is, each entity attribute must be mapped to a table column name.
- Convert unique identifiers to primary keys.
- Convert all relationships to foreign keys.
- Create SQL table.
Base creation
First you need to start the MySQL server. To run it, go to the "Start" menu, then to "Programs", then to MySQL and MySQL Server, select MySQL-Command-Line-Client.
The Create Database command is used to create a database. This function has the following format:
CREATE DATABASE database_name.
The base name restrictions are as follows:
- the length is up to 64 characters and can include letters, numbers, symbols "" and "";
- The name can start with a number, but it must contain letters.

You also need to remember the general rule: any request or command ends with a delimiter. In SQL, it is customary to use a semicolon as a separator.
The server needs to be told which database to work with. There is a USE statement for this. This operator has a simple syntax: USE n database_name.
Creating a SQL table
So, the model is designed, the database is created, and the server is told exactly how to work with it. Now you can start creating SQL tables. There is a Data Definition Language (DDL). It is used to create an MS SQL table, as well as to define objects and work with their structure. DDL includes a set of commands.
SQL Server table creation
Using just one DDL command, you can create various database objects by varying its parameters. To use the Create Table command. The tt format looks like this:
CREATE TADLE table_name,(column_name1 Name _column2 data type [column_constraint],[table_constraints]).

The syntax of the specified command should be described in more detail:
- The table name must be up to 30 characters long and start with a letter. Only alphabetic characters, letters, and the characters "_", "$", and "#" are allowed. The use of Cyrillic is allowed. It is important to note that table names must not be the same as other object names and database server reserved words such as Column, Table, Index, etc.
- For each column, you must specify the data type. Exists standard set used by the majority. For example, Char, Varchar, Number, Date, Null type, etc.

- The Default parameter allows you to set a default value. This ensures that there are no null values in the table. What does it mean? The default value can be a character, an expression, a function. It is important to remember that the type of this default data must match the input data type of the column.
- Per-column constraints are used to enforce data integrity conditions at the table level. There are more nuances. It is forbidden to drop a table if there are other tables dependent on it.
How to work with the base
Large projects often require the creation of multiple databases, each requiring many tables. Of course, it is impossible for users to keep all the information in their heads. For this, it is possible to view the structure of databases and tables in them. There are several commands, namely:
- SHOW DATABASES - shows on the screen all created SQL databases;
- SHOW TABLES - displays a list of all tables for current base data that is selected by the USE command;
- DESCRIBE table_name- shows the description of all columns of the table.
- ALTER TABLE - allows you to change the table structure.
The last command allows:
- add a column or constraint to the table;
- change an existing column;
- delete a column or columns;
- remove integrity constraints.
The syntax for this command is: ALTER TABLE table_name( | | | | [(ENABLE | DISABLE) CONSTANT constraint_name ] | }.
There are other commands:
- RENAME - renaming a table.
- TRUNCATE TABLE - removes all rows from a table. This function may be needed when it is necessary to repopulate the table, but there is no need to store the previous data.
There are also situations when the database structure has changed and the table should be deleted. There is a DROP command for this. Of course, you first need to select the database from which you want to delete the table if it differs from the current one.
The command syntax is quite simple: DROP TABLE Name_tables.

In SQL Access creation tables and their modification is carried out by the same commands listed above.
With CREATE TABLE, you can create an empty table and then fill it with data. But that is not all. You can also immediately create a table from another table. Like this? That is, it is possible to define a table and populate it with data from another table. There is a special AS keyword for this.
The syntax is very simple:
- CREATE TABLE Name_tables[(column_definition)] AS subquery;
- column_definition - column names, integrity rules for newly created table columns, and default values;
- subquery - returns the rows to be added to the new table.
Thus, such a command creates a table with certain columns, inserts into it the rows that are returned in the query.
Temporary tables
Temporary tables are tables whose data is erased at or before the end of each session. They are used to record intermediate values or results. They can be used as worksheets. You can define temporary in any session, but you can use their data only in the current session. SQL temporary tables are created in the same way as usual, using the CREATE TABLE command. In order to show the system that the table is temporary, you need to use the GLOBAL TEMPORARY parameter.

The ON COMMIT clause sets the lifetime of the data in such a table and can do the following:
- DELETE ROWS - clear the temporary table (delete all session data) after each transaction completion. This is usually the default value.
- PRESERVE ROWS - leave data for use in the next transaction. In addition, you can clear the table only after the session ends. But there are features. If the transaction is rolled back (ROLLBACK), the table will be returned to the state at the end of the previous transaction.
The syntax for creating a temporary table can be represented as follows: CREATE TABLE Name_tables,(Name_column1 data type [column_constraint], Name _column2 data type [column_constraint], [table_constraints]).
If you had a need to save the resulting data set returned by an SQL query, then this article will be of interest to you, since we will consider SELECT INTO statement, with the help of which Microsoft SQL Server, you can create a new table and populate it with the result SQL query.
We'll start, of course, by describing the SELECT INTO statement itself, and then move on to the examples.
SELECT INTO statement in Transact-SQL
SELECT INTO- a statement in the language in T-SQL, which creates a new table and inserts the resulting rows from the SQL query into it. Table structure, i.e. the number and names of columns, as well as data types and nullability properties, will be column-based ( expressions) specified in the source select list in the SELECT statement. Typically, the SELECT INTO statement is used to combine data in one table from several tables, views, including some calculated data.
The SELECT INTO statement requires CREATE TABLE permission on the database in which the new table will be created.
The SELECT INTO statement has two arguments:
- new_table is the name of the new table;
- filegroup - filegroup. If no argument is given, the default filegroup is used. This feature is available from Microsoft SQL Server 2017.
Important points about the SELECT INTO statement
- The statement can be used to create a table on the current server; creating a table on a remote server is not supported;
- You can populate a new table with data both from the current database and the current server, and from another database or from a remote server. For example, specify the full database name in the form database.schema.table_name or in the case of remote server , linked_server.database.schema.table_name;
- An identity column in a new table does not inherit the IDENTITY property if: the statement contains a join (JOIN, UNION), a GROUP BY clause, an aggregate function, also if the identity column is part of an expression, comes from a remote data source, or occurs more than once in a list choice. In all such cases, the identity column does not inherit the IDENTITY property and is created as NOT NULL;
- A SELECT INTO statement cannot create a partitioned table, even if the source table is partitioned;
- As a new table, you can specify a regular table, as well as a temporary table, but you cannot specify table variable or a table-valued parameter;
- A calculated column, if there is one in the select list of the SELECT INTO statement, it becomes normal in the new table, i.e. not computable;
- SELECT INTO cannot be used with a COMPUTE clause;
- Using SELECT INTO, indexes, constraints and triggers are not transferred to a new table, they must be created additionally, after the statement is executed, if they are needed;
- The ORDER BY clause does not guarantee that the rows in the new table will be inserted in the specified order.
- The FILESTREAM attribute is not transferred to the new table. The FILESTREAM BLOBs in the new table will be as varbinary(max) BLOBs and have a 2 GB limit;
- The amount of data written to the transaction log during SELECT INTO operations depends on the recovery model. In databases that use the bulk-logged recovery model and the simple recovery model, bulk operations such as SELECT INTO are minimally logged. As a result, a SELECT INTO statement can be more efficient than separate statements to create a table and an INSERT statement to populate it with data.
SELECT INTO Examples
I will execute all examples in the DBMS Microsoft SQL Server 2016 Express.
Initial data
To begin with, let's create two tables and fill them with data, we will combine these tables in the examples.
CREATE TABLE TestTable( IDENTITY(1,1) NOT NULL, NOT NULL, (100) NOT NULL, NULL) ON GO CREATE TABLE TestTable2( IDENTITY(1,1) NOT NULL, (100) NOT NULL) ON GO INSERT INTO TestTable VALUES (1,"Keyboard", 100), (1, "Mouse", 50), (2, "Phone", 300) GO INSERT INTO TestTable2 VALUES (" Computer components"), ("Mobile devices") GO SELECT * FROM TestTable SELECT * FROM TestTable2
Example 1 - Creating a Table with a SELECT INTO Statement with Data Join
Let's imagine that we need to merge two tables and store the result in a new table ( for example, we need to get products with the name of the category they belong to).
Operation SELECT INTO SELECT T1.ProductId, T2.CategoryName, T1.ProductName, T1.Price INTO TestTable3 FROM TestTable T1 LEFT JOIN TestTable2 T2 ON T1.CategoryId = T2.CategoryId --Selecting data from a new table SELECT * FROM TestTable3

As a result, we created a table called TestTable3 and filled it with the combined data.
Example 2 - Creating a temporary table using the SELECT INTO statement with data grouping
Now let's say that we need grouped data, for example, information about the number of products in a certain category, while we need to store this data in a temporary table, for example, we will use this information only in SQL statements, so we do not need to create a full-fledged table.
Create a temporary table (#TestTable) using SELECT INTO SELECT T2.CategoryName, COUNT(T1.ProductId) AS CntProduct INTO #TestTable FROM TestTable T1 LEFT JOIN TestTable2 T2 ON T1.CategoryId = T2.CategoryId GROUP BY T2.CategoryName -- Fetching data from a temporary table SELECT * FROM #TestTable

As you can see, we managed to create a temporary table #TestTable and fill it with grouped data.
So you and I examined the SELECT INTO statement in the T-SQL language, in our book " The T-SQL Programmer's Path» I talk in detail about all the constructions of the T-SQL language ( I recommend reading), and that's all for now!
- How can I combine SELECT statements so that I can calculate percentages, successes and failures in SQL Server?
- SQL: How to select only individual rows based on some property values
- How to choose the product with the highest price of each category?
I need to duplicate the same data in the database, changing only the product id from 1 2.3.... 40
LevelId Min Product 1 x 2 2 y 2 3 z 2 4 a 2
I could do something like
INSERT INTO dbo.Levels SELECT top 4 * fROM dbo.Levels but that will just copy the data. Is there a way I can copy the data and paste it while only changing the Product value?
You are the most on the way - you need to take one more logical step:
INSERT INTO dbo.Levels (LevelID, Min, Product) SELECT LevelID, Min, 2 FROM dbo.Levels WHERE Product = 1
... will duplicate your rows with a different product id.
Also consider that WHERE Product = 1 will be more reliable than TOP 4 . Once you have more than four rows in the table, you can't guarantee that TOP 4 will return the same four rows unless you also add an ORDER BY to the select, however WHERE Product = ... will always return the same and keep going work even if you add an extra row with product id 1 (where you would need to consider changing TOP 4 to TOP 5 etc if you add extra rows).
You can generate a product ID and then upload it to:
< 40) INSERT INTO dbo.Levels(`min`, product) SELECT `min`, cte.n as product fROM dbo.Levels l cross join cte where l.productId = 1;
This assumes that LevelId is an id column that is automatically incremented on insertion. If not:
With cte as (select 2 as n union all select n + 1 from cte where n< 40) INSERT INTO dbo.Levels(levelid, `min`, product) SELECT l.levelid+(cte.n-1)*4, `min`, cte.n as product fROM dbo.Levels l cross join cte where l.productId = 1;
INSERT INTO dbo.Levels (LevelId, Min, Product) SELECT TOP 4 LevelId, Min, 2 FROM dbo.Levels
You can include expressions in the SELECT , either hard-coded values, or something like Product + 1 or whatever.
I expect you probably don't want to put in a LevelId, but leave it there to match your pattern. If you don't want it just strip it from the INSERT and SELECT sections.
For example, you can use CROSS JOIN on a table of numbers.
WITH L0 AS(SELECT 1 AS C UNION ALL SELECT 1 AS O), -- 2 rows L1 AS(SELECT 1 AS C FROM L0 AS A CROSS JOIN L0 AS B), -- 4 rows Nums AS(SELECT ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) AS N FROM L1) SELECT lvl., lvl., num.[N] FROM dbo. lvl CROSS JOIN Nums num
This will repeat 4 times.
